Tiny Recursive Model
- Less is More: Recursive Reasoning with Tiny Networks
- 2025-10; Jolicoeur-Martineau
High-Level Summary
- Introduces Tiny Recursive Model (TRM), a new small model, with hierarchy:
- high-level is current best guess to answer
- low-level does latent reasoning
- Builds on, refines and improves ideas from HRM, without focusing on biological analogies
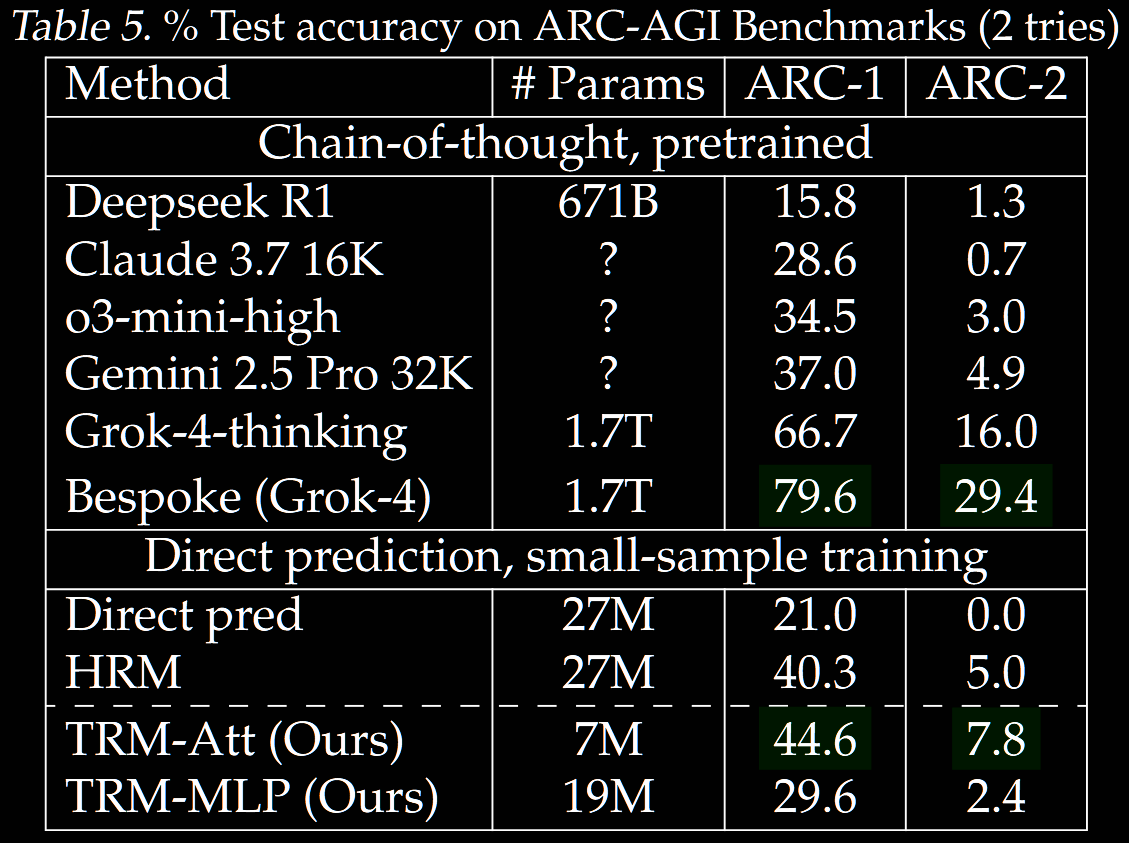
- Gets 45% accuracy on ARC-AGI-1 with only 7M parameters
- Improvements are largely engineering based (imo):
- overall structure is the same
- high-/low-level networks use same parameters
- 2-layer network repeated vs original 4-layer network
- stopping criterion is refined slightly
- a more memory-intensive recursion is used
This overview assumes familiarity with the architecture used in HRM. This can be found in the HRM summary, particularly the Framework section.
HRM Overview
Wang et al (2025/06) introduced the Hierarchical Reasoning Model (HRM) (summary). It is a supervised learning model with two novelties.
-
Recursive hierarchical reasoning consists of recursing multiple times through two small networks: low-level at high frequency and high-level at low frequency, generating latent features and , respectively. Biological motivation is provided.
-
Deep supervision consists of improving the answer through multiple supervision steps, whilst carrying over the two latent features as initialisation for the next step.
Independent analysis by the ARC Prize team (2025/08) (summary) suggests performance on ARC-AGI is driven by the deep supervision, whilst the hierarchical structure only slightly improved performance.
The objective of the current work is to ("massively") improve the recursive hierarchical reasoning, leading to Tiny Recursive Model (TRM). TRM is also significantly smaller.
NB. There is notational clash between HRM and TRM, particularly in the pseudocode (Figures 2 and 3, respectively).
Number of high-/low-level recursions:
- HRM uses high-level recursions, each of which consists of low-level recursions.
- TRM uses high-level recursions, each of which consists of low-level recursions.
(Fortunately) by default, HRM uses , which is symmetric.
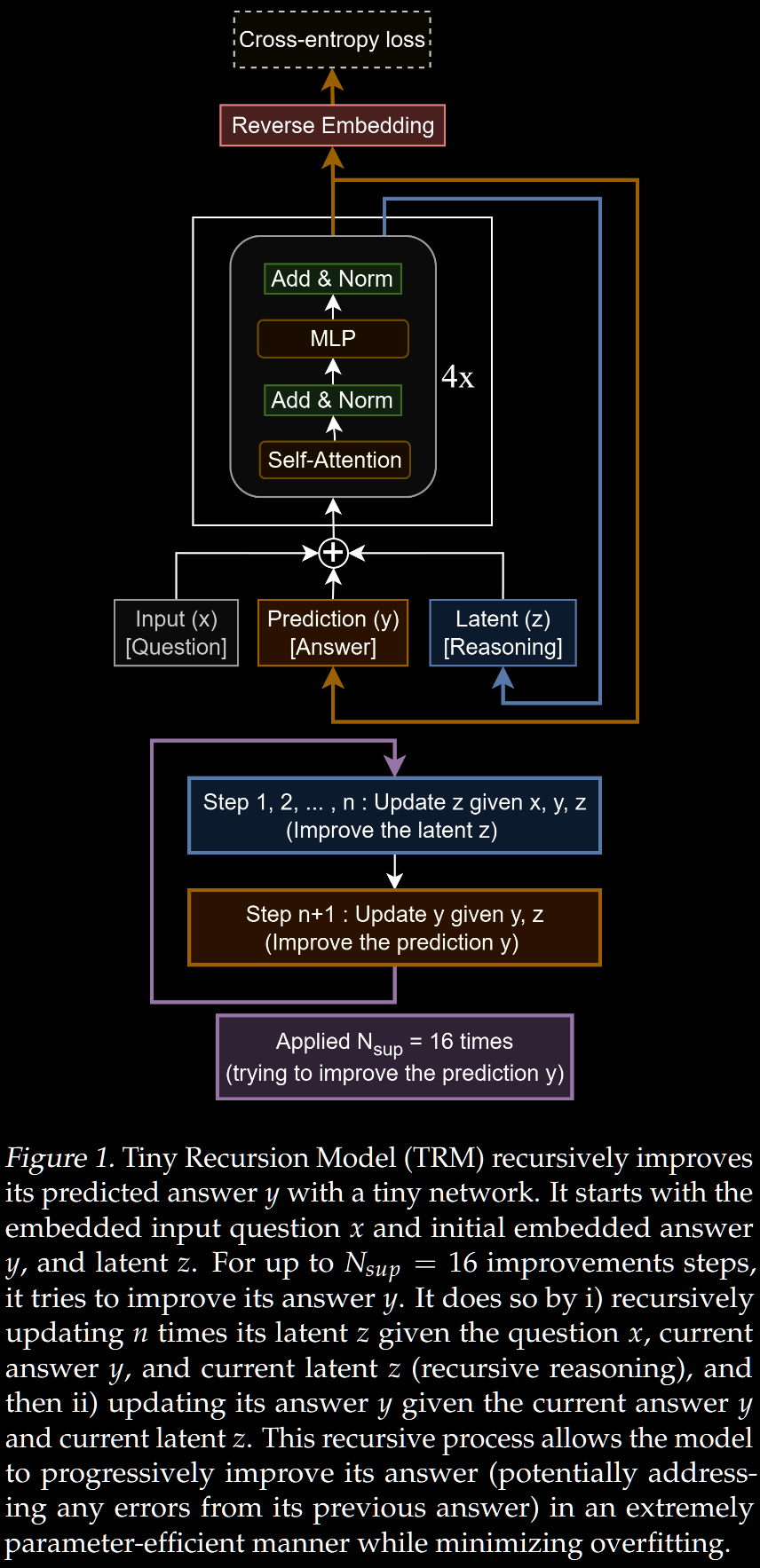
TRM interprets as the current output and as the latent reasoning, so (often, but not always) uses notation and .
TRM uses for the maximum number of supervision steps, whilst HRM uses .
From HRM to TRM
Single, Shallower Network
HRM uses two networks: high-level and low-level . TRM replaces these with a single network , halving the parameter count in one fell swoop.
Increasing the number of layers is a natural way to (try to) increase the model capacity. Trying this, the TRM author found overfitting. On the contrary, decreasing the number of layers whilst scaling the number of recursions proportionally, they found 2 layers (instead of 4 in HRM) maximised generalisation. This halves the parameter count again, whilst (approximately) maintaining the emulated depth .
Depth of Hierarchical Structure
The HRM authors justify using two hierarchies via biological arguments, including comparisons with actual brain experiments on mice. No ablation over the number of layers is given. The TRM author gives a simpler explanation:

- is simply the current (embedded) solution;
- is a latent (reasoning) feature.
With this interpretation, there is no apparent reason for splitting the latent feature into multiple features. Nevertheless, an ablation table is provided. There, high-level recursions are used.
The latent feature can be transformed into an (embedded) solution by , but shouldn't be. Their Figure 6 highlights that does correspond to the (current) solution, whilst does not.
Twice the Forward Passes with ACT
HRM uses adaptive computational time (ACT) during training to optimise the time spent on each data sample. It comes at a cost: the Q-learning objective requires an extra forward pass to estimate whether to stop now or continue. The current parameters are used, so this forward pass cannot be reused after the parameters have been updated.
TRM learns only a halt probability, through binary cross-entropy loss vs the correct solution. This removes the need for an (expensive) extra forward pass. No significant difference in generalisation was observed.
Optimal Number of Recursions
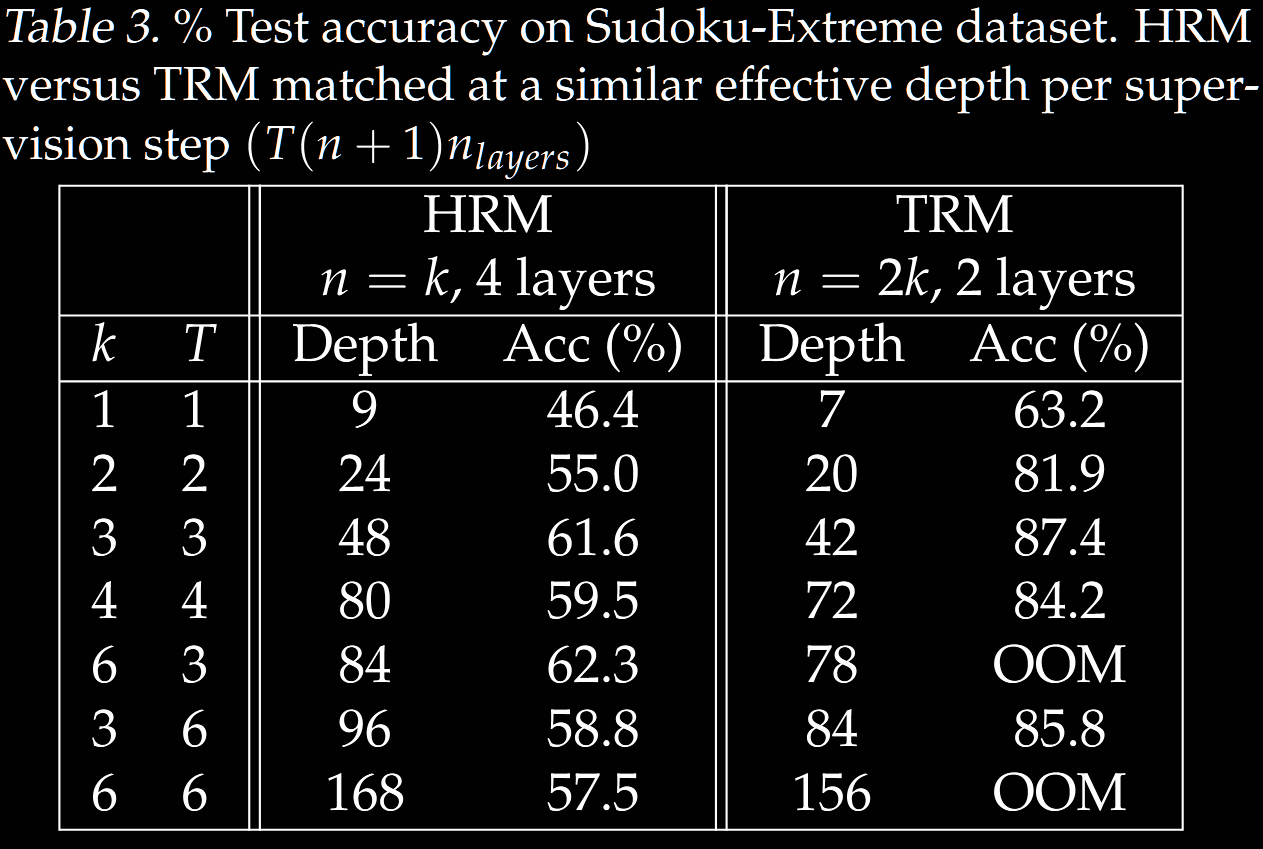
An ablation study across varying values of and was conducted.
- They found , equivalent to recursions optimal in TRM.
- In contrast, HRM uses , equivalent to recursions.
TRM requires backpropagation through a full recursion process (see below). Thus, increasing too much leads to OOM errors.
One-Step Gradient Approximation
HRM only backpropogates through the last two of the six recursions. This reduces the memory footprint significantly, and saves compute. It is justified via the implicit function theorem, which allows computation to the gradient at a fixed point in only one step.
The legitimacy of the application is questionable:
- it requires both and to be at (or, near) the fixed point;
- this is far from guaranteed when , as in their experiments.
TRM applies a full recursion process containing evaluations of and one of (now both ). Multiple backpropagation-free recursion processes can still be used to improve .
An increase in generalisation on Sudoku is claimed, albeit without a proper ablation. This comes at the fairly significant cost of backpropping through the full process—see, eg, OOM errors in Table 3 when each latent recursion has more than 8 steps.
Exponential Moving Average
On small data, (the TRM author claims that) HRM tends to overfit quickly and then diverge. An exponential moving average, a common technique in GANs and diffusion models used to improve stability, is integrated into TRM.
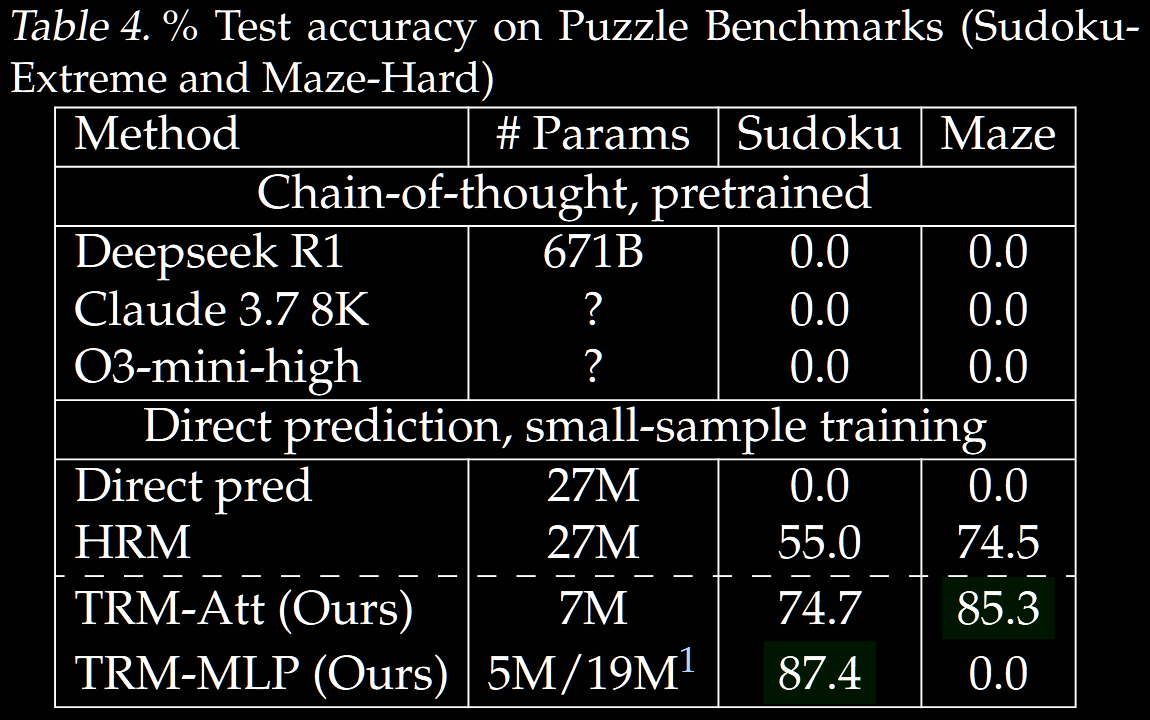
Results
TRM is tested on puzzle benchmarks (Sudoku and mazes) and ARC-AGI (both 1 and 2, pass@2). The same data structure and augmentation is used as in HRM; see the Data Usage and Augmentation section in the HRM summary for details.