Hierarchical Reasoning Model
- Hierarchical Reasoning Model
- 2025-06; Wang, Li, Sun, Chen, Liu, Wu, Lu, Song, Yadkori
High-Level Summary
- Introduces Hierarchical Reasoning Model (HRM), a new small model
- A recurrent architecture modelled on hierarchical and multi-timescale processing in human brains
- Attains significant computational depth whilst maintaining both training stability and efficiency
- Small model: only 27M parameters
- operators without pre-training: task-specific training
Elevator Pitch
Current LLMs primarily employ CoT techniques to reason. These suffer from computational challenges, including requiring extensive data. Also, are they really reasoning? Or, are they recalling reasoning they've seen? Their struggles on novel tasks, such as in ARC, hint at the latter.
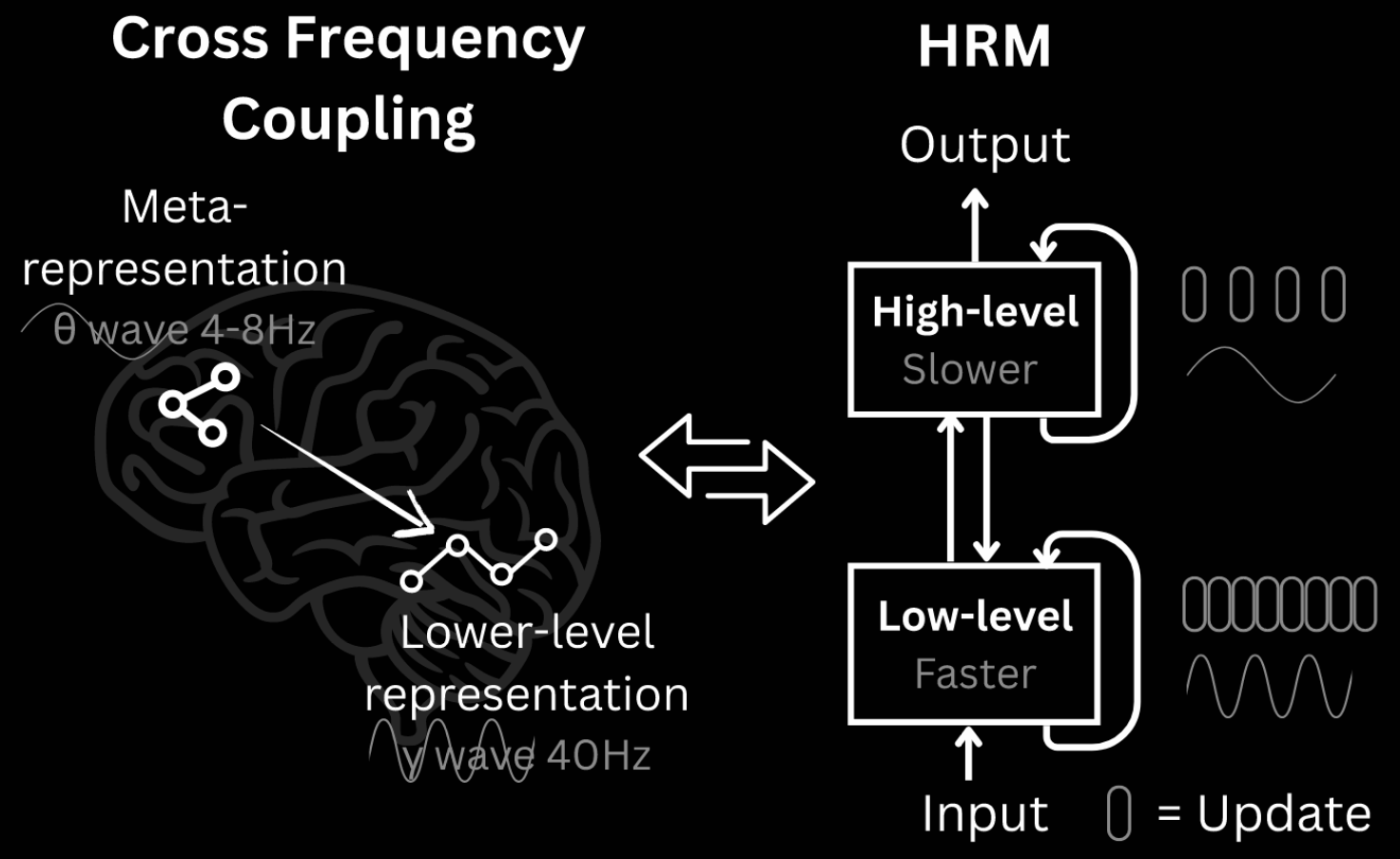
Inspired by hierarchical processing and temporal separation in the human brain, HRM has two interdependent recurrent modules:
- a high-level module responsible for slow, abstract planning;
- a low-level module handling rapid, detailed computations.
The model operates without pre-training of CoT data. Rather, training data is required for the task at hand—eg, ARC-AGI-2 or Maze-Hard. This checkpoint is not saved for future tasks: the model is randomly initialised for each task.
HRM outperforms much larger models with significantly longer context windows on ARC, and achieves excellent performance on complex tasks, such as Sudoku or optimal path finding in large mazes, where CoT models fail completely.
Detailed Motivation
LLMs largely rely on CoT prompting for reasoning. CoT externalises reasoning into language, breaking down complex tasks into simpler, intermediate steps. Such a process lacks robustness and is tethered to linguistic patterns; it requites significant training data and generates many tokens, resulting in large computational cost. Humans certain don't reason this way.
Enter latent reasoning: the model internalises computations. This aligns with the understanding that language is tool for communication, not the substrate of thought itself. Latent reasoning is fundamentally constrained by a model's effective computational depth. Naively stacking layers leads to vanishing gradients. Recurrent architectures often suffer from early convergences—internal state stabilises, and further calculations are useless, and rely on computationally expensive backprop through time (BPTT) training.
The human brain organises computation hierarchically across different regions, operating at different timescales. Slow, higher-level areas guide fast, lower-level circuits via recurrent feedback loops. This increases the effective depth, without the cost of BPTT.
HRM is designed to significantly increase the effective computational depth. It features two coupled recurrent modules:
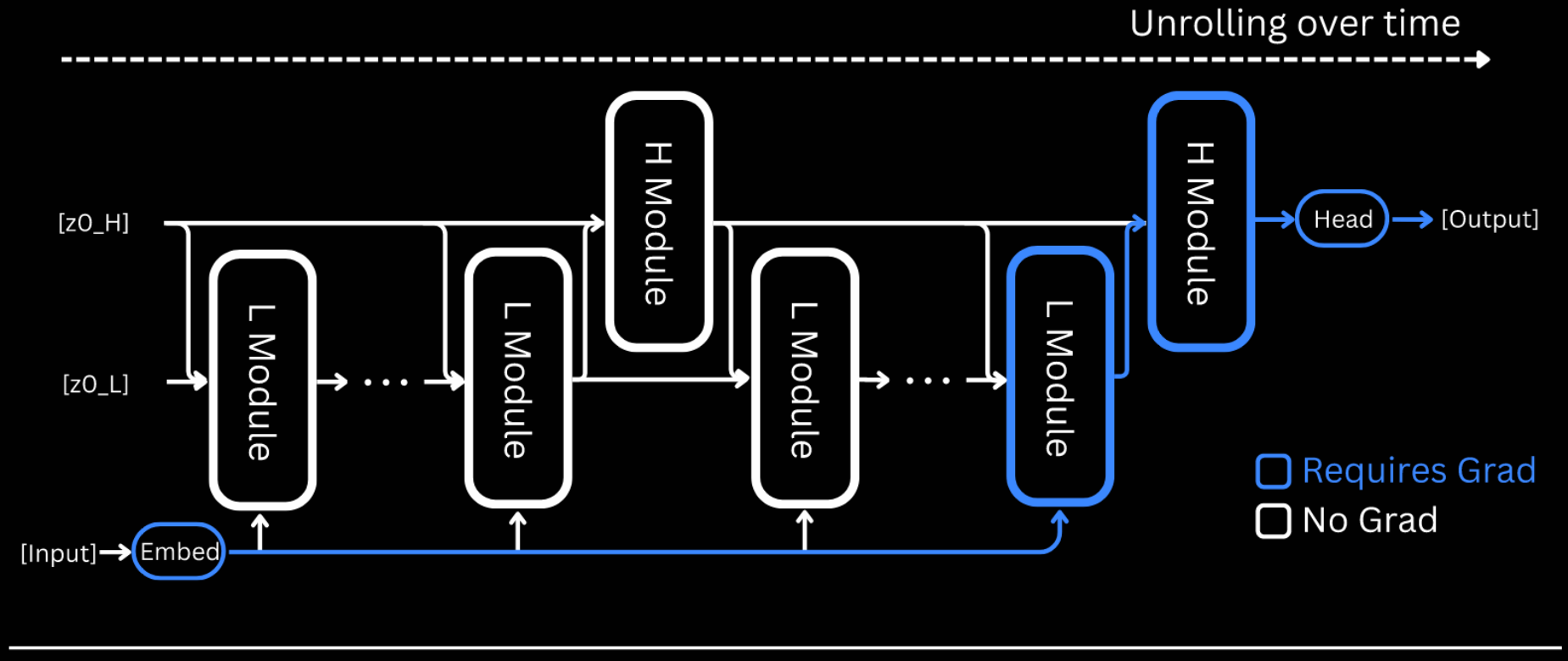
- high-level for slow, abstract reasoning;
- low-level for fast, detailed computations.
The slow module (H) advances only after the fast one (L) has reached a local equilibrium, at which point it is reset. This avoids the early convergence of standard recurrent models.
Further, a one-step gradient approximation for training HRM is used, maintaining memory footprint (vs for timesteps in BPTT), applying backprop in a single step at the equilibrium point.
HRM
The HRM consists of four learnable components:
- an input network ;
- a low-level recurrent module ;
- a high-level recurrent module ;
- an output network .
The models' dynamics unfold over high-level cycles, each consisting of low-level steps. The modules each keep a hidden state .
First, the framework is outlined, including some brief architectural details, then the training recipe explained. The section closes with detailed pseudocode for training.
Framework
The HRM maps an input vector to an output prediction vector as follows.
-
Convert the input into a working representation :
-
At each timestep , the L module updates its state and the H module updates only if a multiple of as follows: Alternatively, one could only define the H state every T updates—ie, the 'real' updates, . The HRM paper mixes the two versions, unfortunately.
-
After full cycles, a prediction is extracted from the hidden state of the H module:
This entire three-step process represents a single forward pass. A halting mechanism (discussed below) determines whether the model should terminate, in which case is output, or continue with an additional forward pass.
Whilst convergence is crucial for recurrent networks, it also limits their effective depth—iterations the (almost) convergence point add little value. HRM addresses this by alternating between L-convergence and H-iteration: a single H update establishes a fresh context for the L module, 'restarting' its convergence.
HRM uses a sequence-to-sequences architecture: both the input and output are represented as sequences.
- The embedding layer converts discrete tokens into vector representations.
- The output head , given by , transforms hidden states into token probability distributions .
- Both low- and high-level recurrent modules and , respectively, are encoder-only Transformer blocks, with identical architectures and dimensions.
Training Recipe
The training recipe consists of three main aspects. These are outlined below; detailed descriptions are given in collapsible sections, but may be skipped.
-
Deep Supervision. Given a data sample , multiple forward passes of HRM are run. Let and denote the hidden state and parameters, respectively, at the end of segment .
- .
- .
- .
-
Adaptive Computation Time (ACT): halting strategy and loss function. With deep supervision, each mini-batch is used for up to steps. A halting strategy, for early stopping during training, is learned through a Q-learning objective. It greatly diminishes the time spent per example on average, at least for the Sudoku-Extreme dataset (only reported). It does, however, require an extra forward pass with the current parameters to determine if halting now is preferable to later.
Adaptive Computational Time (ACT): Halting strategy and loss function.
The adaptive halting strategy uses Q-learning to adaptively determine the number of segments (forward passes). A Q-head uses the final state of the H module to predict the Q-values: The half/cont(inue) action is chosen using a randomised strategy.
- Let denote the maximum number of segments (a fixed hyperparameter).
- Let denote the minimum number of segments.
- The halt action is selected if and either or .
The Q-head is updated through a Q-learning algorithm. The state of its episodic Markov decision process (MDP) at segment is and the action space is .
- Choosing terminates the episode and returns the binary reward indicating correctness: .
- Choosing yields a reward of and the state transitions to .
The Bellman equations define the optimum:
The optimum is interpreted as the probability of being correct given halting/continuing, given that the current state is .
Thus, the Q-learning targets for the two actions are given as follows: This last expression corresponds to the probability of being correct given continuing at step : either stop at step () or continue beyond ().
We can now define our loss function: [ \mathcal L^m = \textsf{Loss}(\hat y^m, y)
- \textsf{BinaryCrossEntropy}(\hat Q^m, \hat G^m). ] Minimising this enables both accurate predictions and sensible stopping decisions.
-
One-Step Gradient Approximation. Assuming that reaches a fixed-point through recursion, the implicit function theorem with one-step gradient approximation allows approximation of the gradient by backproping only the last step.
The legitimacy of the application to this set-up, with so fewer steps in the iteration, is questionable.
Theoretical foundation for one-step gradient approximation.
The one-step gradient approximation is based on deep equilibrium models, which employ the implicit function theorem to bypass BPTT.
In idealised HRM behaviour, during the -th high-level cycle, in state , the L module iterates its state to a local fixed point . This can be expressed in the form where . The H module then performs a single update using this converged state: In other words, for some , where . Its fixed point satisfies The implicit function theorem allows calculation of the exact gradient of the fixed point wrt through the Jacobian :
Unfortunately, evaluating and inverting is prohibitively expensive. But, for in a neighbourhood of the fixed point, . This leads to The gradients of the low-level fixed point can be approximated similarly: Plugging these into the previous display gives the final approximated gradients: these depend only on the functions .
Pseudocode
# HRM forward pass
def hrm(z, x_, N=2, T=2):
zH, zL = z
# iterate modules without gradient
with torch.no_grad():
# update L-level module
for i in range(N * T - 2):
zL = L_net(zL, zH, x_)
# update H-level module
if (i + 1) % T == 0:
zH = H_net(zH, zL)
# last iteration with gradient
zL = L_net(zL, zH, x_)
zH = H_net(zH, zL)
return (zH, zL), output_head(zH), q_head(zH)
# Adaptive Computational Time
class ACT:
# parameters
def __init__(self, M_max, eps=0.1):
self.M_max = M_max
self.M_min = 1 + bern(eps) * unif([0, ..., M_max - 1])
# when to halt
def ACT_halt(self, q, y_hat, y_true):
target_halt = (y_hat == y_true)
loss = 0.5 * binary_cross_entropy(q["halt"], target_halt)
return loss
# when to continue
def ACT_cont(q, last_step: bool):
if last_step:
target_cont = q["halt"]
else:
target_cont = max(q["halt"], q["cont"])
loss = 0.5 * binary_cross_entropy(q["cont"], target_cont)
return loss
# Deep supervision
for x_input, y_true in train_dataloader:
# Prepare inputs
x_ = input_embeddings(x_input)
z = z_init
act = ACT(M_max=16)
# Multiple forward passes
for _ in range(act.M_max):
# HRM forward pass
z, y_hat, q = hrm(z, x_)
# two-part loss
loss_ce = softmax_cross_entropy(y_hat, y_true)
_, _, q_next = hrm(z, x) # extra forward pass
loss_act = act.halt(q_next, y_hat, y_true)
loss = loss_ce + loss_act
# Update gradients and optimiser
z = z.detatch()
loss.backward()
opt.step()
opt.zero_grad()
# early stopping
if q["halt"] > q["cont"]:
break
Results
Despite the impressive results, with such a small model, the results section is actually somewhat sparse.
Benchmarks
Three different types of tasks are considered: ARC-AGI, Sudoku and (finding the optimal path in) Mazes. For all benchmarks, HRM models were randomly initialised and trained in the sequence-to-sequence set-up, using the input--output pairs:
- the input and output grids given in ARC-AGI;
- the initial and completed Sudokus;
- the initial maze and the one augmented with the optimal path.
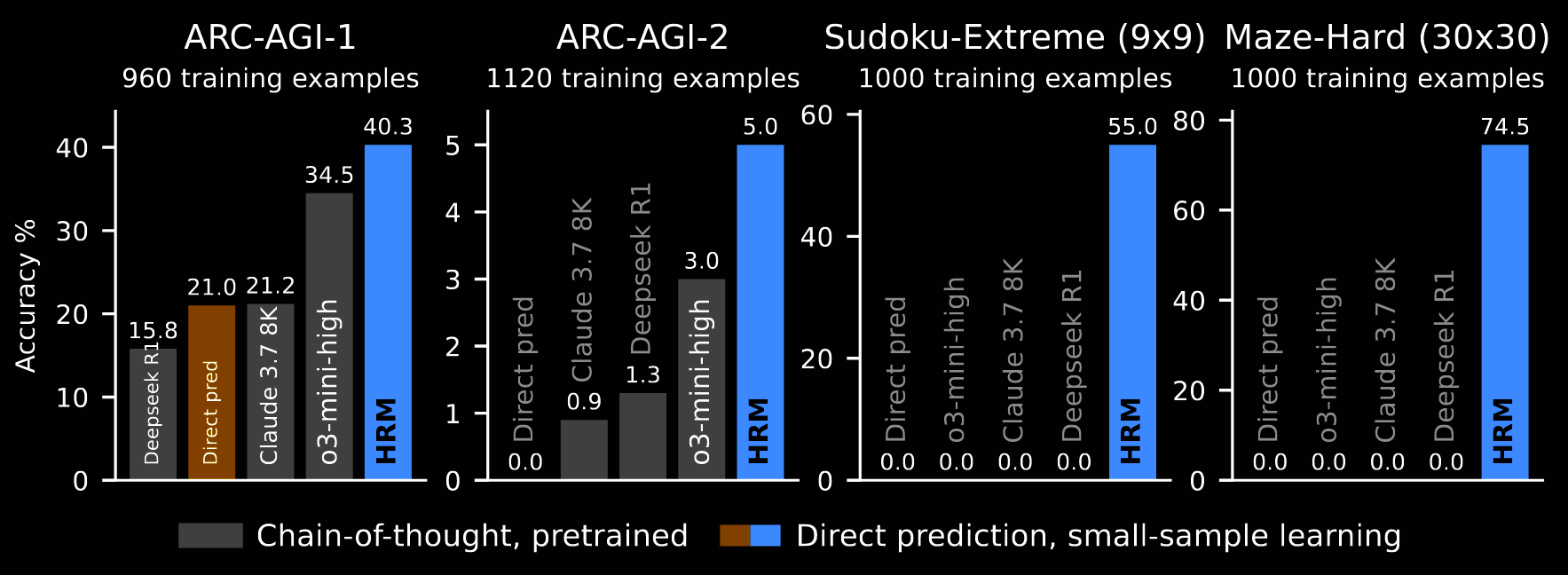
The resulting performance is shown in the previous figure, repeated here. These results are attained with just ~1000 training examples per task, and without pre-training or CoT labels. Various augmentations are implemented for ARC-AGI and Sudoku, but not for the mazes.
The baselines are grouped based on whether they are pre-trained and use CoT (o3-mini-high, Claude 3.7 8K and Deepseek R1) or neither. The "direct pred[iction]" baseline retrains the exact training set-up of HRM, but swaps in a Transformer architecture—eight layers, identical in size to HRM.
-
ARC-AGI. HRM outperforms all the LLMs. On ARC-AGI-1, even "direct pred[iction]" outperforms Deepseek R1 and matches the performance of a domain-specific network, carefully designed for learning the ARC-AGI task from scratch, without pre-training.
-
Sudoku and Maze. HRM significantly outperforms the baselines here. The benchmarks require lengthy reasoning traces, without much complexity—each step is simple, but there are many of them—making them particularly ill-suited to LLMs.
Data Usage and Augmentation
Data augmentation is relied heavily on for ARC-AGI and Sudoku; it is not used for mazes.
For ARC-AGI, the training dataset starts with all demonstration/example and test/problem input–output pairs from the training set and all demonstration/example pairs from the evaluation set. The test/problem pairs from the evaluation set are saved for test time. The dataset is augmented (eg, colour permutations, rotations, etc). Each pair is prepended with a learnable special token representing its task id.
At test time, for each test/problem pair in the evaluation set, 1000 augmented variants are generated and solved; the inverse augmentation is applied to obtain a prediction. The two most popular predictions are chosen as the final outputs.
To emphasise, the training set is a flattened collection of simple input—output pairs, augmented with the task id. They are not batched by task id. There is no, "Here are X example input–output pairs of grids. The problem is to find the (hidden) output grid corresponding to [this] input grid."
For Sudoku, band and digit permutations are applied. There is no concept of a task to which multiple datapoints belong.
Visualisation
HRM performs well on complex reasoning tasks, raising a question:
"What underlying reasoning algorithm does the HRM neural network actually implement?"
The intermediate stages are visualised. At each timestep , a preliminary forward pass through the H module is performed, then fed through the decoder: The (intermediate) prediction is visualised in the figure below; its caption explains what is going on.

- In the Maze task, HRM appears to explore several poential paths simultaneously, subsequently eliminating blocked/inefficient ones.
- In Sudoku, the strategy resembles a depth-first search, exploring potential solutions and backtracking when it hits dead ends.
- It approaches ARC differently, making incremental adjustments to the grid, iteratively improving until the solution, rather than trying and backtracking. That said, it only solved 5% of ARC-AGI-2, so possibly this is a bad choice.
Inspecting every timestep (manually updating ) feels questionable. The low-level module should be thought of as 'latent reasoning', whilst the high-level one is the current guess (not yet decoded). It could make more sense to only look at the evolution of .