ARC Prize Team's HRM Analysis
- The Hidden Drivers of HRM's Performance on ARC-AGI
- 2025-06; Chollet, Knoop, Schürholt
High-Level Summary
- The Hierarchical Reasoning Model (HRM) is a small (~27M), 'hierarchical' model
- A recurrent architecture modelled on hierarchical and multi-timescale processing in human brains
- Attains significant computational depth whilst maintaining both training stability and efficiency
This overview assumes familiarity with the architecture used in HRM. This can be found in the HRM summary, particularly the Framework section.
Summary
The official ARC team have analysed HRM:
First, the results were approximately reproduces on the semi-private sets.
- ARC-AGI-1 @ 32%: impressive for such a small model, but not state of the art.
- ARC-AGI-2 @ 2%: non-zero score shows some signal, but not material progress.
A series of ablation studies call into question the narrative around HRM.
- The "hierarchical" architecture had minimal performance impact vs similarly sized transformer.
- The "outer loop" refinement drove the performance, particularly at training time.
- Cross-task transfer learning had limited benefits; most of the performance comes from memorising solutions.
- Pre-training task augmentation is critical; little impact at inference time.
Findings 2 & 3 suggest the approach is fundamentally similar to ARC-AGI without Pretraining (Liao & Gu, '24).
Analysis
The four main components of the HRM paper are investigated: the model architecture, the high–low hierarchical computation, the outer refinement loop and the use of data augmentation.
Specifically, the following were tested, taken verbatim from the relevant section.
- "Hierarchical" H and L loop performance contributions
- What performance does HRM provide over a base transformer?
- What impact does varying the hierarchical compute have?
- Varying the max "halt or continue" loops
- How well does the ACT grader do compared to a fixed number of loops (with no decision to halt refinements)?
- Impact of cross-task transfer learning
- What is the impact of the inclusion of the training set tasks and the ConceptARC tasks at training time, compared to only training on the evaluation tasks?
- Augmentation count
- Varying the number of augmentations that were created from each task.
- Model/training variations (size and duration)
Finding #1: Minimal Impact from "Hierarchical" Architecture
Two experiments were performed.
- Vary the amount of iterations in the hierarchical components.
- Replace the HRM with a similarly sized transformer.
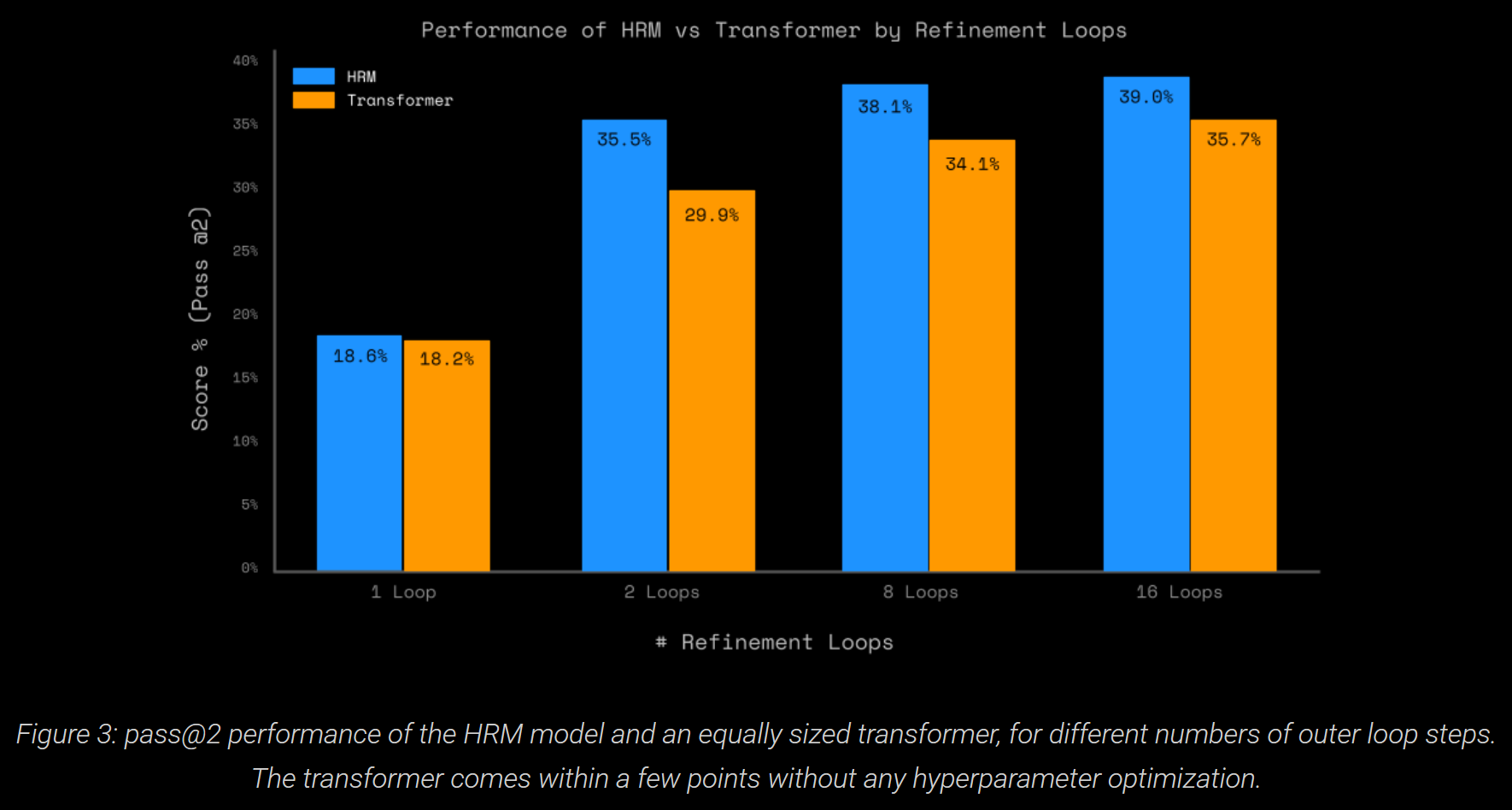
On ARC-AGI-1, a regular transformer comes within ~5pp of the HRM model, without hyperparameter optimisation. Varying the number of H- and L-level steps vs the baseline (L=2 and H=2) only decreased the performance.
These suggest that, whilst the HRM architecture provides a small benefit, it is not the main driver of HRM's performance on ARC-AGI.
Finding #2: "Outer Loop" Refinement Drives Gains
The model feeds its high-level output back into itself, allowing iterative refinements. It uses "adaptive computational time" (ACT) to control the number of iterations. To analyse this, the maximum number of outer loops during training (forcing maximum number during inference, as in the HRM implementation) was varied. Below, the mark "ACT N Loops" means a maximum of N loops, with ACT early stopping.
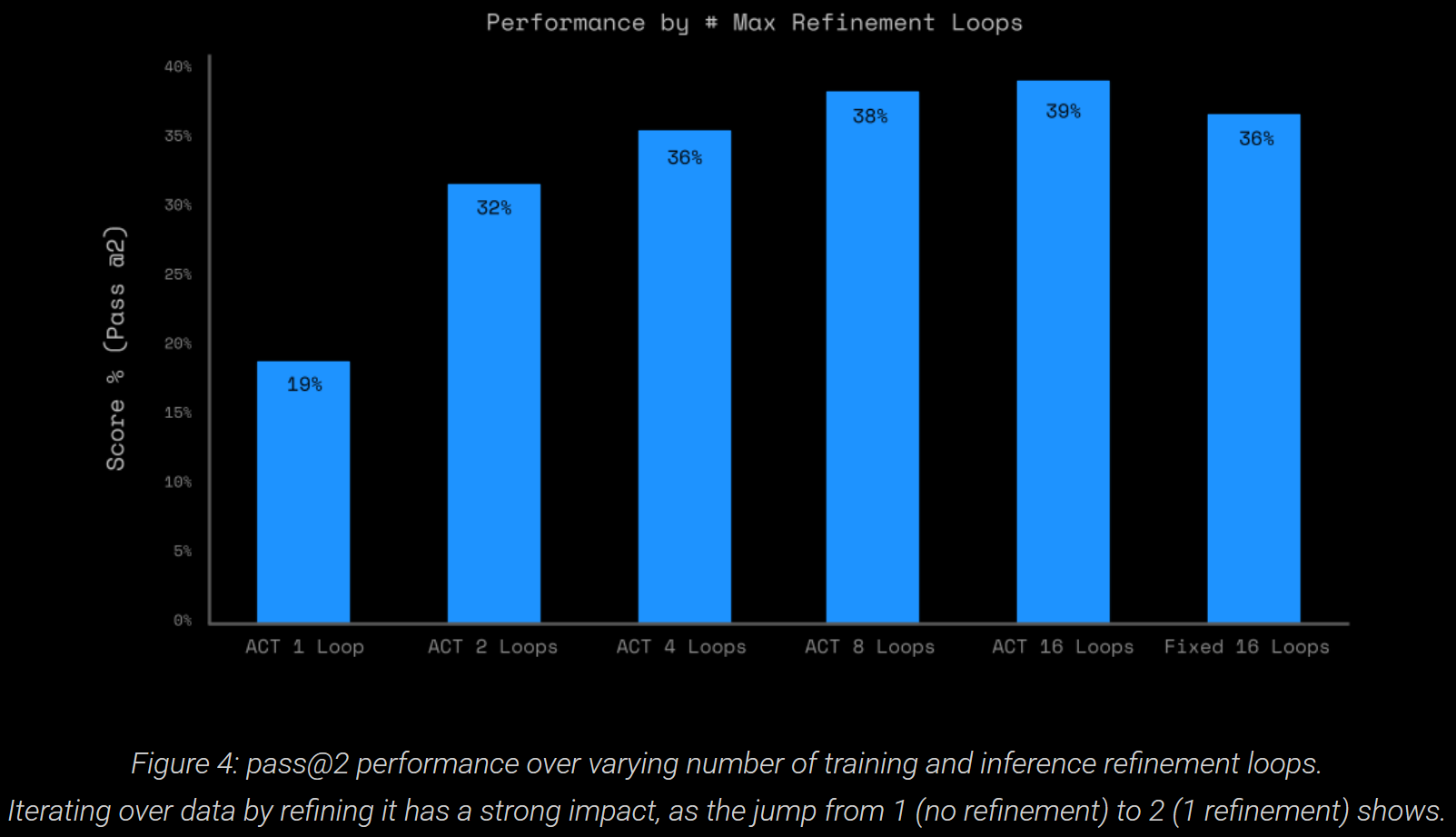
Clearly, this parameter has a large impact, doubling ~20% to ~40%. Interestingly, using ACT with maximum of 16 vs fixed 16 is a slight improvement.
To understand refinement during training vs inference, the number of loops was varied during inference too.
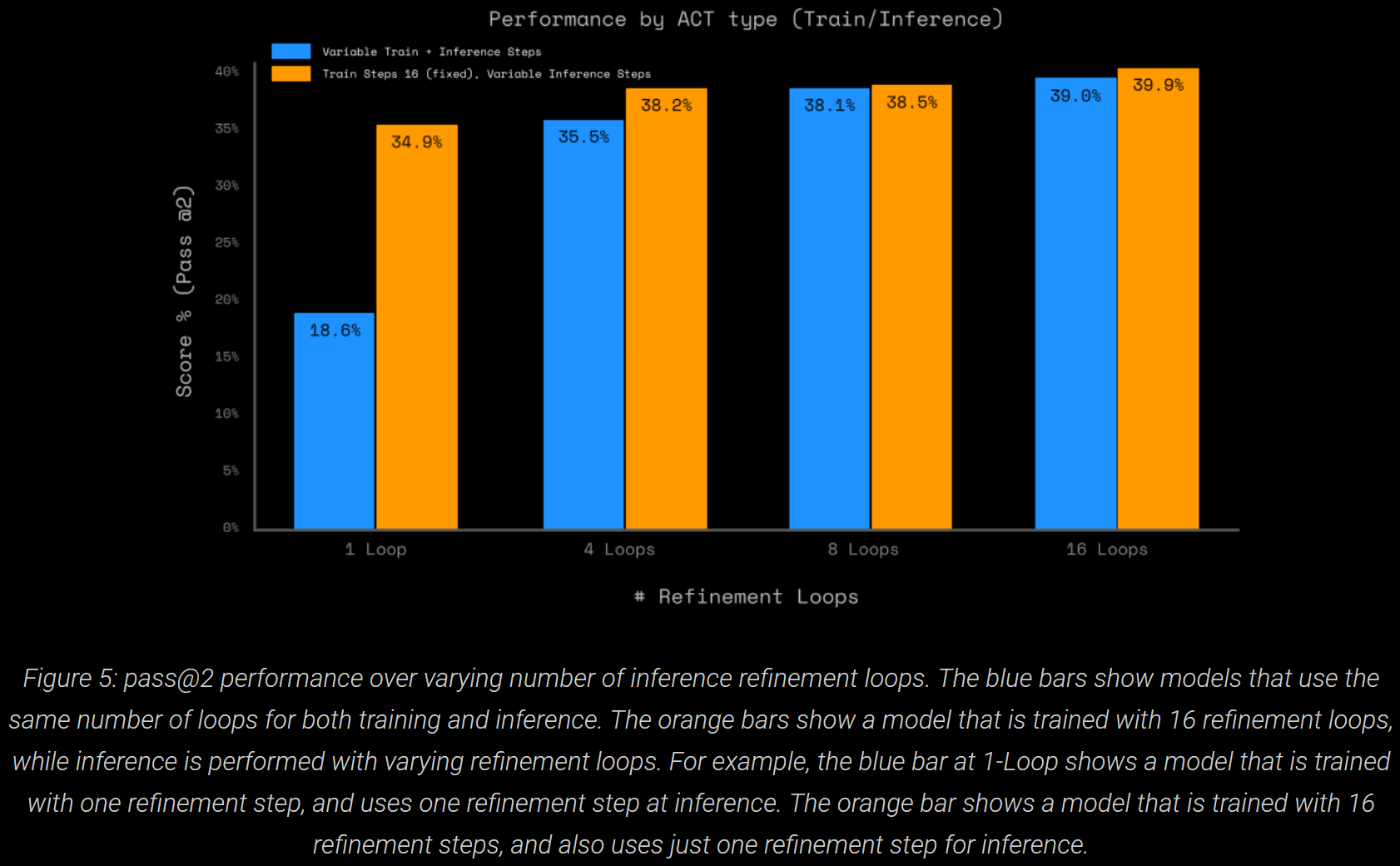
Training with more refinement makes a big difference (doubles, >15pp) when no inference refinement is allowed. More than 4 refinement loops for inference has little impact.
Finding #3: Limited Impact of Transfer Learning
The original HRM is trained on augmented version of the demonstration (example) pairs, from both the training and evaluation sets; ConceptARC is also used.
NB. This does not imply data leakage: the model never sees, at training time, the test (problem) pairs. Fundamentally, this is a zero-pretraining test-time training approach. To emphasise, it uses the example pairs, as well as augmented versions, from the entire evaluation set to train.
This certainly raises questions about its generalisability: it relies heavily on data augmentation, including for other tasks such as Sudoku.
This is similar to ARC-AGI without Pretraining (Liao & Gu, '24), and amounts to using the model as a kind of program synthesis substrate: gradient descent on example pairs encodes in the weights a program that performs the task.
To understand cross-task transfer learning, the 400 training tasks and 160 ConceptARC tasks were removed. This dropped performance from 41% to 31%. The ARC Prize team suggests the performance is driven by test-time training. I'm not so sure.
- As they note, there is some cross-task learning between the 400 tasks in the eval set—which comprise >40% of all the data.
- Perhaps cross-task learning is important, but 400 samples is enough to get good performance (31%). The remainder bump this up non-trivially (to 41%).
The ARC Prize team suggest a stronger version: train on just one evaluation task (with augmentations). This is Liao & Gu's set-up. They speculate the results would be similar (21% pass@2).
Another interesting test would be to train solely on the training set, and evaluate on the eval set. Augmentations can still be used: create n augmented versions → make predictions → undo augmentation → majority selection. The weights wouldn't be updated during these augmentations, though.
Finding #4: Pretraining Task Augmentation Is Critical
HRM makes predictions for all augmented versions of a task, then reverts the augmentation to place in the original format. Majority voting selects the final candidate(s). Two modifications are tested.
- Changing the maximum number of augmentations when compiling the dataset.
- Changing the maximum number of predictions used for majority voting.
The latter is restricted to reducing the number, since HRM can't process augmentation types not encountered during training.
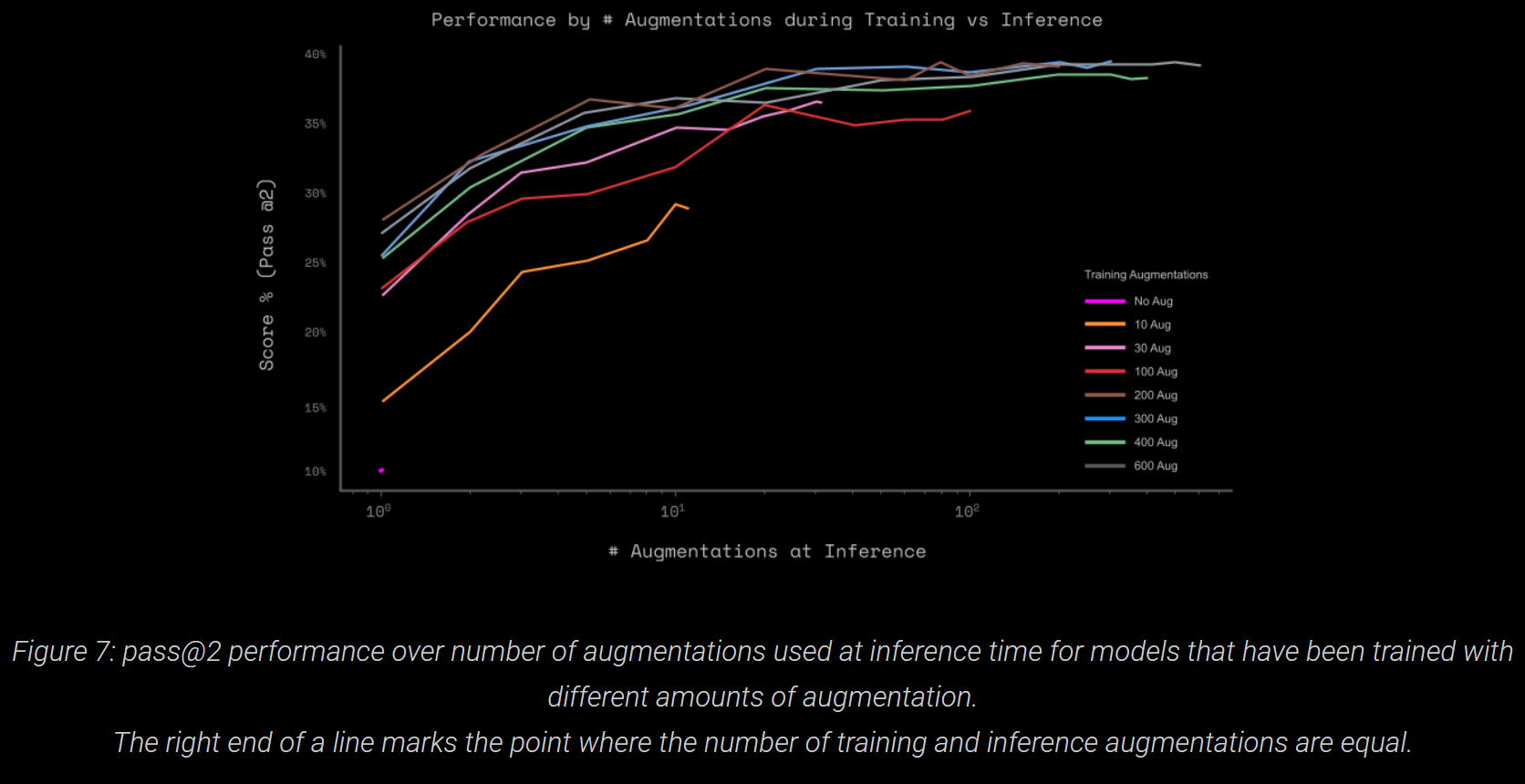
Two trends are exhibited.
- Augmentations help significantly. But, 300 is plenty, vs the 1000 used by HRM; in fact, 30 gets within 4pp of the max.
- Augmentation during training appears to be more important than for a bigger voting pool: "the lines at the top flatten out quickly" (and the horizontal axis is on a log scale).
Other Technical Observations
First and foremost, the dataset: HRM "flattens" all input–output pairs. Each pair gets an id, which consists of the task hash and a code for the augmentation applied.
At training and inference time, the model only receives the input and id—there is no few-shot context with other examples of the task. The model has to learn to relate an id to a specific transformation.
To that end, the model feeds the id into a large embedding layer; without this, it wouldn't know what to do with an input. This presents a major limitation: the model can only be applied on puzzles with ids it's seen in training.
In conversation with the ARC Prize team, the HRM authors claimed that changing the embeddings for few-shot contexts is complex engineeringwise. As such, inference data has to be part of the training dataset.
Last, whilst the refinement loop clearly has significant impact on performance, HRM is purely transductive: at no point is the underlying program explicit. The ARC Prize team hypothesise this won't generalise.