Hierarchical Reasoning Model
- HRM-Agent: Training a recurrent reasoning model in dynamic environments using reinforcement learning
- 2025-10; Long Dang, David Rawlinson
High-Level Summary
- Supervision+known vs RL+unknown
- HRM has only been applied to supervised, static, fully-observable problems
- HRM-Agent is fully-RL trained to navigate dynamic and uncertain maze environments
- It replaces the linear+softmax output head with a DQN head
- Utilising previous work
- HRM does not reuse computations from previous steps (resets latent variables)
- But they may contain valuable information about (unknown) state of the environment
- HRM-Agent 'carries forward' these, giving a warm start and faster convergence
Details of the HRM architecture can be found in my HRM summary. Familiarity with this is assumed in this summary.
HRM-Agent
Architecture
HRM-Agent uses "the simplest possible model architecture to adapt the HRM [into] an RL agent".
- It is trained entirely with RL, from a random initialisation.
- The output head (linear+softmax) is replaced with a Deep-Q Network (DQN) head, with actions selected via an -greedy policy - during evaluation.
- The hidden size is reduced to 64, leading to approx 0.5M parameters
MSE loss between the current model's predicted -values, for the current environment step, and bootstrapped target values:
here, is a copy of the current model and is a terminal-step indicator, precluding rewards beyond the end of an episode.
The Adaptive Computation Time (ACT) component, allowing early exiting during training, is disabled. This facilitates convergence analysis of the recurrent state , with its 'low' () and 'high' () levels of hierarchy.
Reusing Calculations
The model how has two time-like dimensions.
- Environment time: the steps within an (RL) episode.
- Recurrent time: (HRM) recursions inside an episode.
HRM randomly initialises the latent states and at the start of every forward pass (which consists of ≤16 recursions). In many environments, particularly ones that are not fully observable from the start, the contents of from the previous environment timestep is still relevant for the current one. In fact, consistency is often important for plan execution.
Two HRM-Agent variants are evaluated.
- Carry : randomly initialise the latent state for first environment timestep, then "carry forward" to next - no gradients are propagated through environment time.
- Reset : randomly initialise the latent state for each forward pass.
Experiments and Results
The HRM paper focussed on ARC-AGI, Sudoku and maze path-planning. The authors adapt the latter to a dynamic, partially-observed problem by placing and removing obstacles. The agent is given the full state at the start of each episode, but the state changes throughout the episode - the has to find this out for themselves.
EntryNotFound (FileSystemError): Error: ENOENT: no such file or directory, open '/mnt/c/Users/samot/projects/summaries-with-sam/papers/...'
-
Four-rooms. Precisely one door is closed at all times. Each environment step, the closed door is randomly reassigned with probability . This is infrequent enough that it is often worth finding an alternative path when reaching a closed door.
-
Random maze. The maze begins with a regular grid of permanent walls, along with 10 fixed walls and 5 dynamic walls, whose locations are both randomly assigned. Each door independently opens/closes with probability at each environment timestep.
The experiments were designed with the following purposes:
- validate that HRM can be adapted to learn to reason successfully in an RL setting;
- explore the dynamics of the recurrent 'reasoning' process to verify that the model can utilise earlier computation as the environment changes.
Validation of Concept
Figure 3 displays the proportion of episodes in which the agent reaches the goal. Each training run is displayed as a separate series.
Success in the random maze environment demonstrates a generalised ability to plan paths. The large number of possible mazes, along with small parameter count, reduces the change that the agent has just learned the optimal path for each.
Analysis of Recurrence: "Carry " vs "Reset "
The authors (claimed to have) hypothesised that the recurrent state contains part (or all) of the planned path to the goal, even though the agent only moves one square at a time. This is because the best next action depends on knowledge of a full viable path.
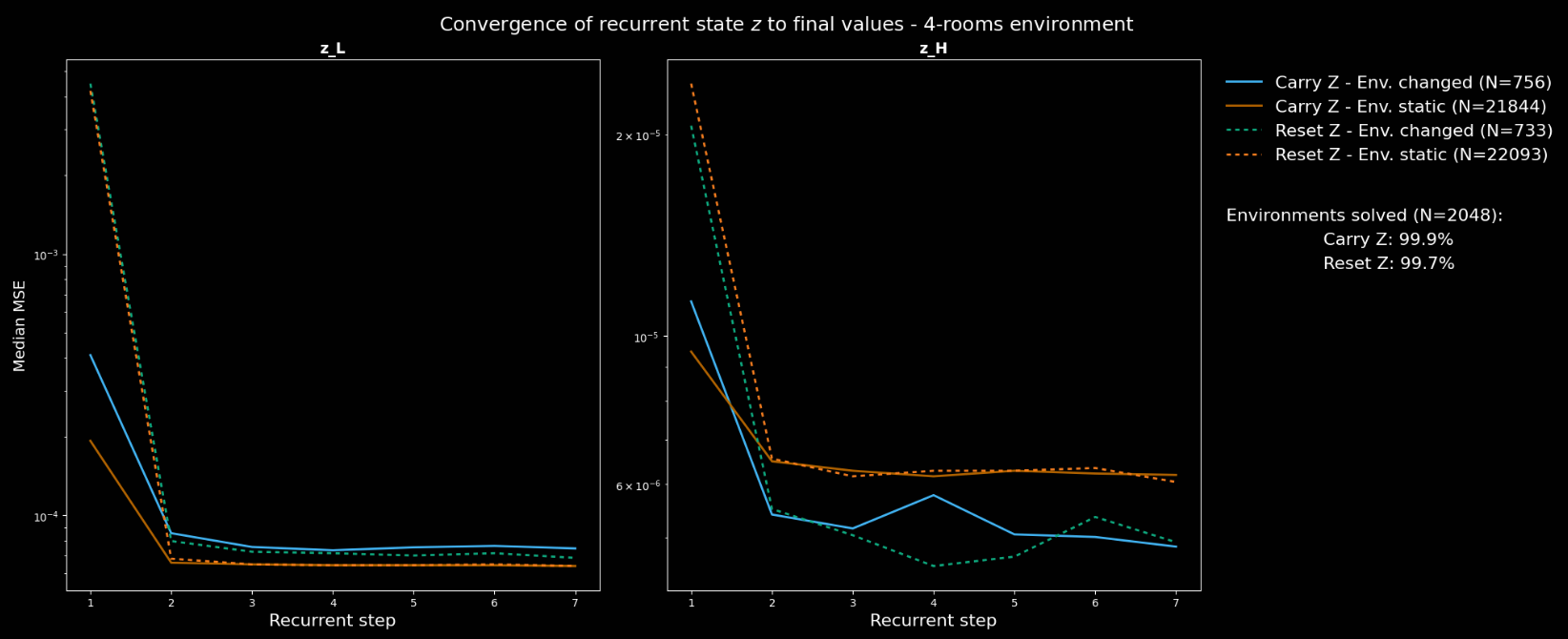
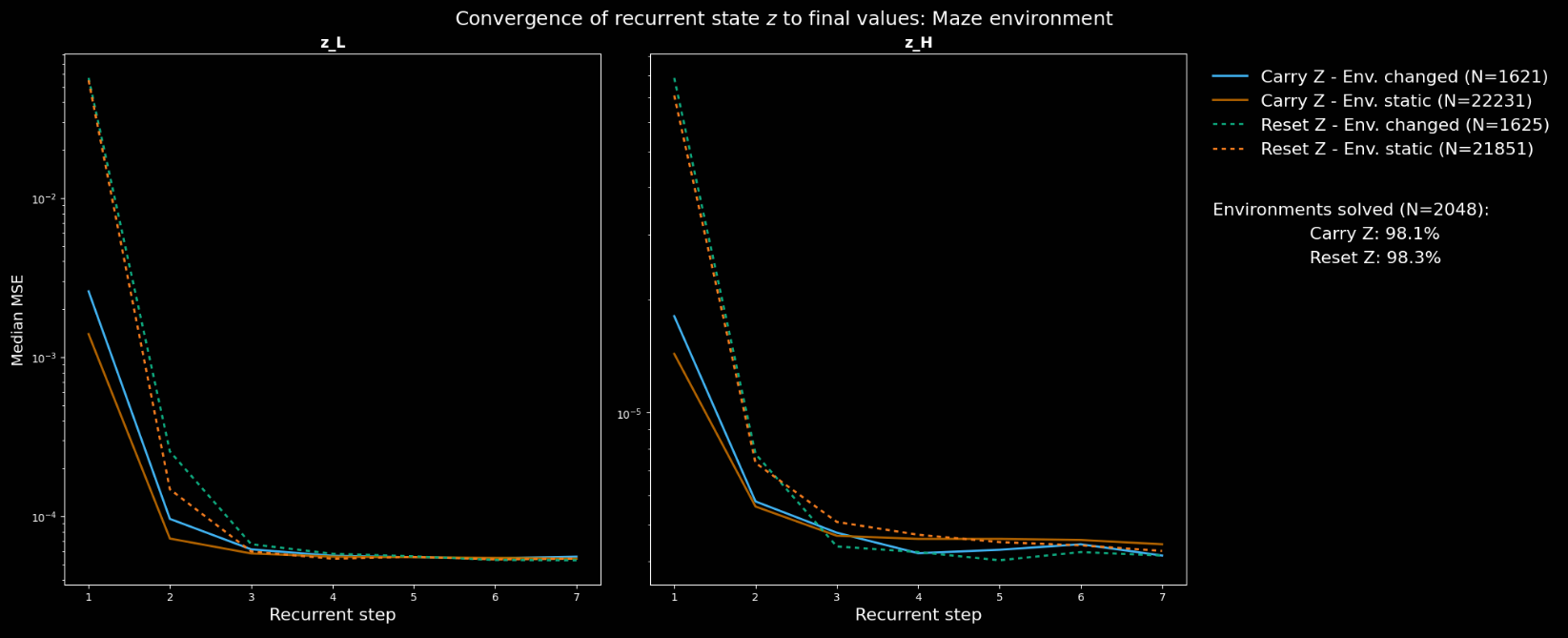
Four conditions were analysed (two choices for two options): carry/reset ; environment has/hasn't changed. For each, the MSE between (recurrent timestep ) and (the final one, using the HRM notation)
The authors ask us to consider the following points before viewing the plots.
- If the environment changes in a way which requires a different plan/path, the initial should look very different to the final one. Otherwise, they should look similar.
- The defined conditions do not distinguish between material and irrelevant changes, which may dilute any measured effect.
- In "Carry ", if the model benefits from knowledge of its existing plan, convergence should be faster and distance between initial and final values of smaller.
The authors describe their results, shown below, as "broadly agree[ing]" with these statements.
- The initial values are closer to the previous converged one in the "Carry " vs "Reset " version.
- The final distances are somewhat indistinguishable.
- The convergence rate is slightly faster in the random maze environment, but not in 4-rooms.
- In 4-rooms, the new converged value is further away from the previous one when the environment changes, but this doesn't replicate in the random maze environment.
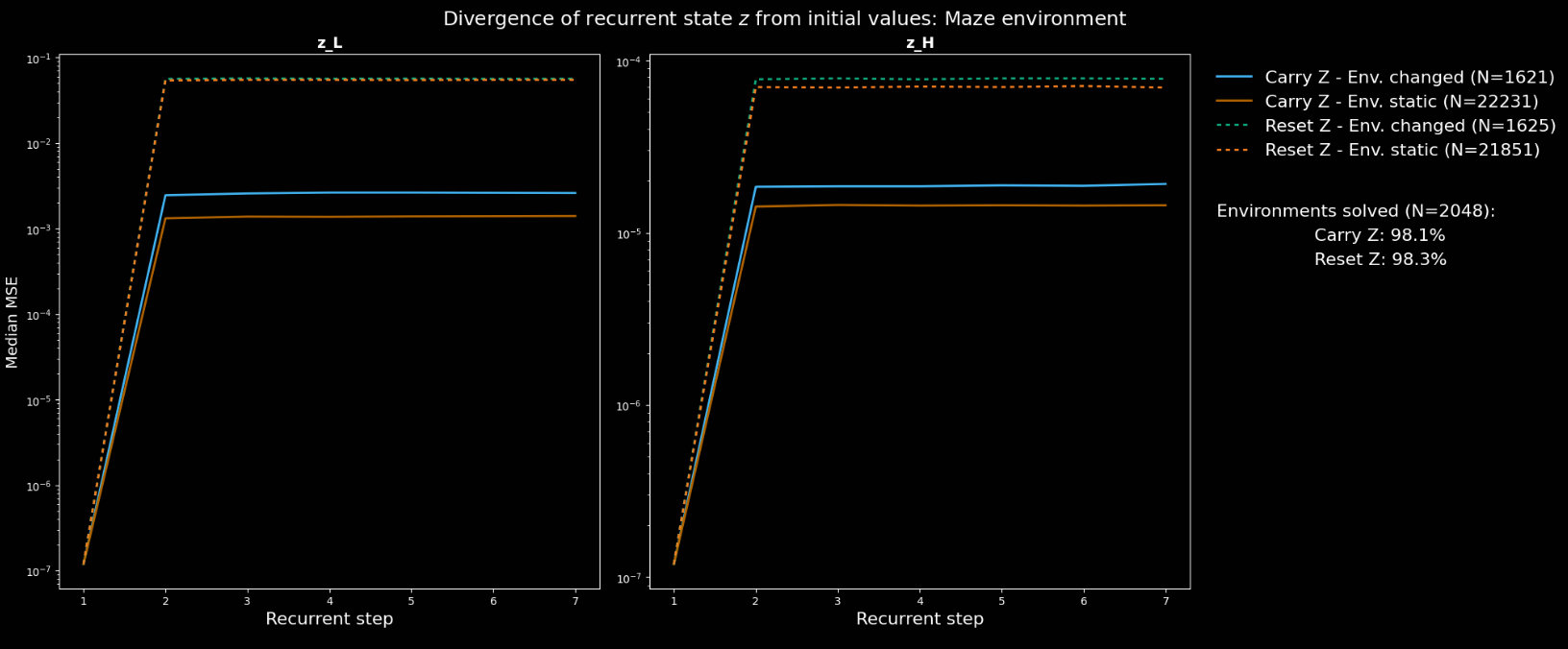
The divergence between the first and -th converged recurrent states - ie, the latent output of the first and -th forward passes - in the random maze environment. Here, the final latent state is indeed significantly closer to the initial in the "Carry " version. The authors say that suggest that resultant paths are more consistent in this case.
These rather inconsistent results make any conclusions difficult. This is ML, though, so that doesn't stop the authors: "these support the belief that the agent is constructing a representation of the path to the goal in its latent state (ie, reasoning), before generating the next action from this plan".
Conclusion
- A lightweight 'agentic' HRM framework, which is able to solve some simple dynamic and/or partially observed problems. Certainly a baseline for future work
- "Carrying forward" the latent states from one full call to the next shows benefit in some scenarios
- Respect to the authors for having said they hypothesised certain results which didn't come to pass - they could've just not said that, and we'd be none the wiser