CoT2 Summary
Continuous Chain of Thought Enables Parallel Exploration and Reasoning
- 2025-05; Gozeten, Ildiz, Zhang, Harutyunyan, Rawat, Oymak
High-Level Ideas
-
Implements continuous thoughts to offer a "richer and more expressive alternative [to discrete CoT]"
-
Rather than sampling the last token, a superposition of tokens through the softmax: typically either the full distribution, or an average over discrete tokens
-
For specific applications (such as searches), these softmax outputs are trained to match an empircial output—eg, averages over reachable states after steps
-
Policy-optimisation via GRPO (when tokens are sampled) is described
-
Some genuine improvement appears to be shown, but might be a little focused on concrete problems (eg, searches)
Related Papers
-
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
-
Text Generation Beyond Discrete Token Sampling (Mixture of Inputs)
-
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
-
Let Models Speak Ciphers: Multiagent Debate through Embeddings
-
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Some Details
The paper introduces a continuous-token approach. Classical CoT feeds the thought token back into the LLM to produce the next thought token. Their underlying idea is very similar to soft thinking: instead of sampling a single token, it samples/deterministically selects a continuous superposition. Two primary methods are suggested.
- Base (aka soft thinking): deterministically feed full distribution each step
- MTS (multi-token sampling): sample discrete tokens and average them; CoT corresponds to
For more formal details on how to implement this, see the summary on soft thinking or mixture of inputs, for example.
Unlike soft thinking or mixture of inputs, this paper introduces a training approach: continuous supervised fine tuning (CSFT). This fits a target distribution for the within-trace tokens. For example, in a graph search, the -th target distribution could be an average over (an embedding of) the vertices reachable within steps. The idea is that it allows the models to explicitly track multiple "teacher traces" in parallel. The strategy is fitted to the problem, rather than a generic idea of 'reasoning'/'intelligence'. On top of this, GRPO-style RL is employed for policy optimisation. We detail the two parts below.
CSFT (Supervised Training)
A target distribution is specified for each , where is the (preset) length, and is the one-hot distribution on the target token. If is the LLM-provided distribution for the -th token, the final loss is the sum of the relative entropies:
By minimising this loss, the model is taught to learn the soft targets . Two ways of providing prefixes to the language model are considered.
-
Teacher forcing, in which each step is conditioned on the ground-truth prefix: for .
-
Self-feeding in which each step autoregressively uses the model's previously generated outputs: or for .
The authors found teacher forcing to lead to better performance; at inference time, on potentially unseen problems, the model runs in an autoregressive manner, of course.
Additionally, a discrete baseline is considered, in which is required to be a token in the vocabulary—in other words, the are one-hot distributions, rather than arbitrary ones, over the vocab.
GRPO (Reinforcement Learning)
The evaluation are all question–answer style, making them ideal for GRPO. Sparse rewards are used: for the correct final answer (regardless of the intermediate tokens) and otherwise. The GRPO implementation appears pretty standard; see my summary of GRPO for the DeepSeekMath paper for general GRPO details.
Two methods for policy optimisation—namely, defining the policy ratio in the GRPO objective—are proposed.
-
Multi-Token Sampling (MTS). A rollout is emulated by sampling discrete tokens and averaging them. Suppose the step- tokens are with respective probabilities under the new/old policy. The policy ratio for these continuous steps is the ratio of geometric means:
-
Dirichlet Sampling. A scaling hyperparameter is introduced, and a distribution is sampled from the Dirichlet distribution , given an LLM distribution . The continuous token is formed by . The policy ratio is the ratio of the Dirichlet densities: This parallels computation for discrete actions, but replaces the categorical pmf with a continuous Dirichlet pdf.
For the final step, in either case, only one token is selected, so the policy ratio is just , where is the index of the chosen token.
Results
Two benchmark-styles are considered; both require exploration over states. Let be the set of all states that could result from building upon step (ie, an element of ), with some initial state. For each , assign a probability reflecting how many times occurs in a search:
where is the number of times state appears amongst all expansions at step .
-
Minimum Non-Negative Sum Task: given a list of integers, choose signs such that is minimised.
- Supervision for CoT2: at step , there are partial sums; if token appears many times as a partial sum of length and otherwise.
- Supervision for discrete model: a correct chain of partial sums—ie, —is provided.
-
ProntoQA and ProsQA: graph search tasks requiring exploration over multiple paths.
- Each question in ProntoQA asks whether a certain target word is reachable from a root word within a fixed number of steps ( here), whilst for ProsQA it asks which of two is reachable.
- The counts are based on vertices reachable from the root within steps.
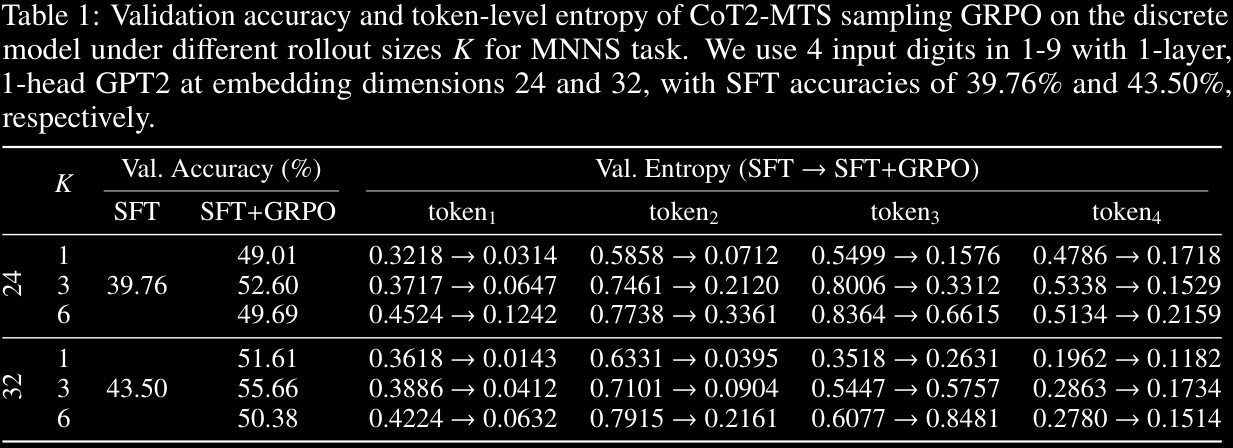
CoT2-MTS improves validation accuracy relative to the discrete baseline. Smaller values lead to larger reductions in token-level entropies, suggesting it learns to commit to fewer tokens. A curriculum on may help: start small, and gradually increase.
Appendix C.2 shows that CoT2 with CSFT performs well once the embedding dimension is large, and Dirichlet sampling (rather than MTS) can improve performance even further.
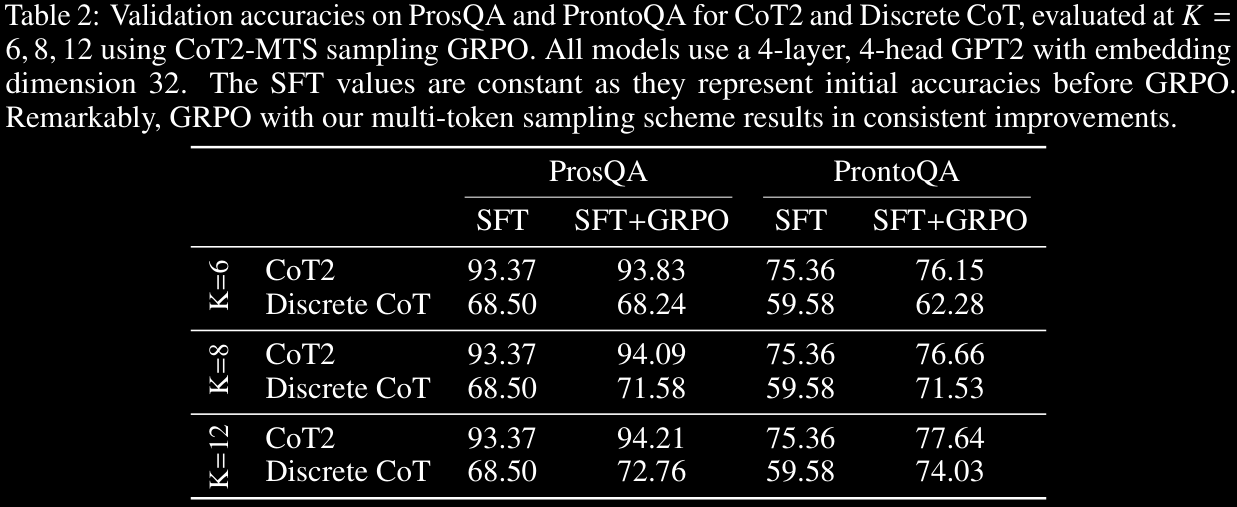
All choices seem to work pretty well, with fairly significant improvements for CoT2 over Discrete CoT. The difference is particularly pronounced in ProsQA, but only minor on ProntoQA.
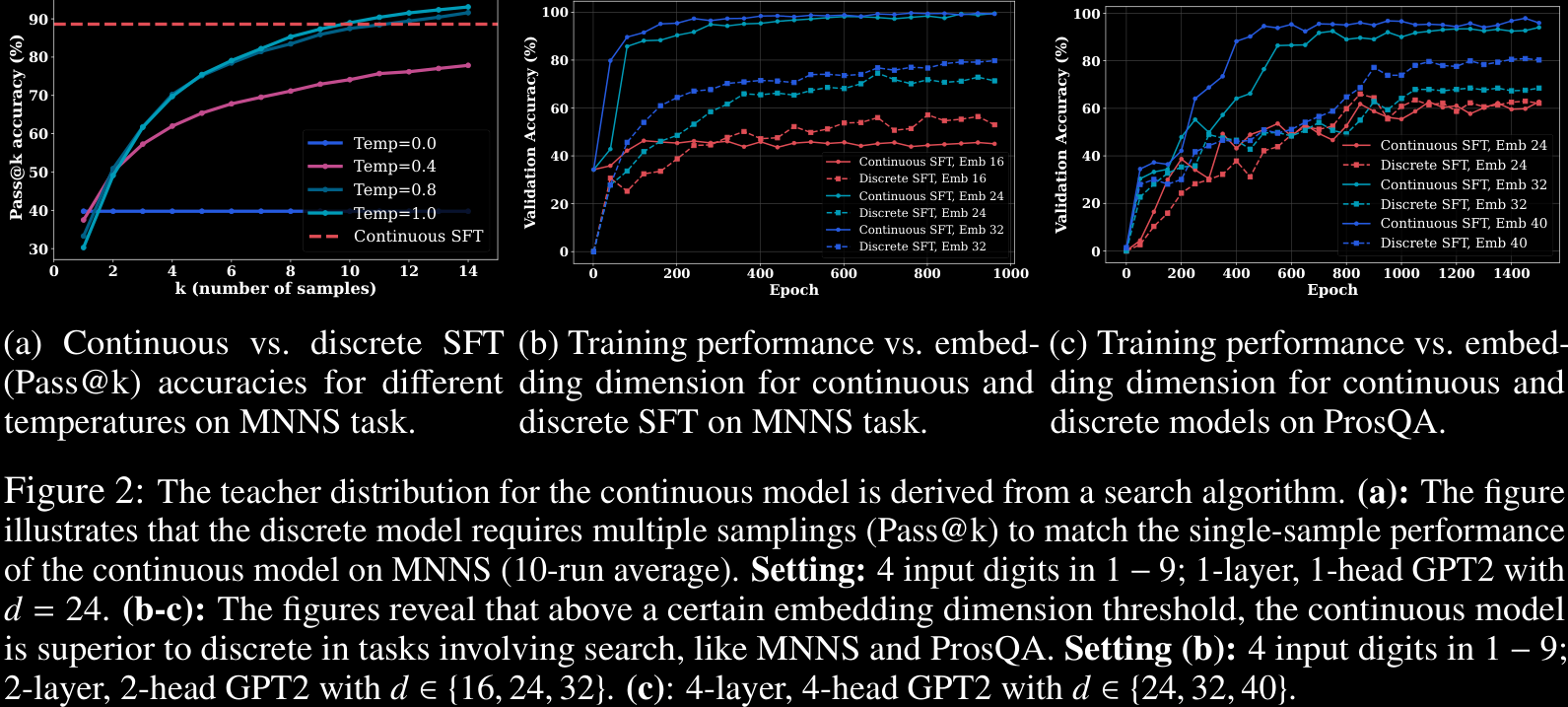
Finally, we display a figure from earlier in the paper. They show that continuous SFT outperforms the discrete baseline once the embedding dimension is high enough, and actually convergence may be faster too; see Figures 2b and 2c. Figure 2a demonstrates that the discrete model requires multiple samples (Pass@k) to approach a single attempt from the CSFT CoT2.
Further results are given in Appendix C of the paper.