DeepSeekMath Summary
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- 2024-07; DeepSeek-AI
High-Level Summary
- Introduce DeepSeekMath 7B, a LLM focused on mathematical capabilities
- Achieves comparable performance with Minerva 540B, even with ~77x fewer parameters
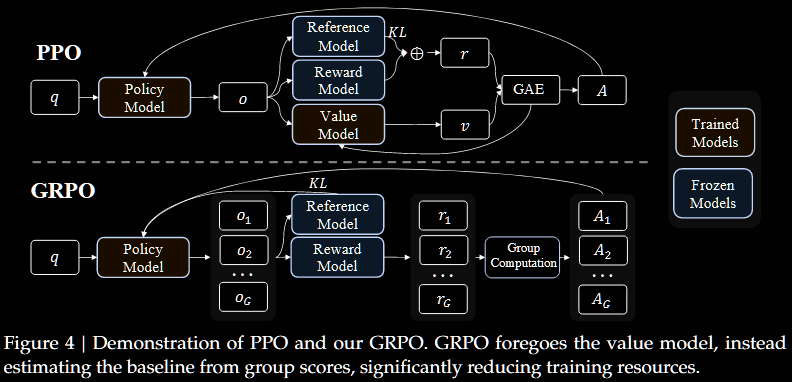
- Introduces and uses Group Relative Policy Optimisation (GRPO): GRPO foregoes the critic model, instead estimating the baseline from group scores
- Provide a unified paradigm to understand different models, and use to explore reasons behind the effective RL
The main theoretical contribution is the introduction of GRPO, which extends PPO.
Evolution: PPO to GRPO
Proximal Policy Optimisation (PPO) is an actor—critic RL algorithm which maximises a surrogate objective:
with
- / are the current/old policy models;
- / are questions/outputs sampled from the question dataset/old policy;
- is the advantage based on the rewards and a learned value function;
- is a clipping hyperparameter for stabilising training;
- is a hyperparameter governing per-token KL penalty.
The value function is treated as a baseline in estimating the advantage. In the LLM context, usually only the last token is assigned a reward score, which may complicate training a value function that is accurate at each token. Group Relative Policy Optimisation (GRPO) addresses this:
- it removes the need for additional value-function approximation;
- instead, it uses the average reward of multiple sampled outputs (to same question) as the baseline.
More specifically, for each question , GRPO samples a group of outputs from the old policy and maximises an analogous surrogate objective
except that now the advantage is replaced with the estimate based on the rewards of the outputs inside each group only; in all its glory,
An unbiased estimator of is used, namely
One of the key benefits of GRPO over PPO is not needing to learn/evaluate the advantage , which can be costly. Two options are mentioned: "outcome" in #4.1.2 and "process" in #4.1.3. For example, in "outcome",
where is the reward for and ; in particular, the same advantage is prescribed to each timestep .
Key Differences: PPO vs GRPO
-
Overview:
-
Traditional RL methods rely on external evaluators (critics) to guide learning
-
GRPO evaluates groups of responses relative to each other
-
This can lead to more efficient training, but requires multiple role-outs per example (the group of responses)
-
-
Critic model (or lack thereof):
-
PPO requires a separate critic model to estimate the value, which often requires training
-
PPO's critic model typically comparable size to policy model, bringing substantial memory and computational burden
-
GRPO avoids this need, instead proposing a 'group' of outputs and calculates an advantaged based on the these rewards
-
GRPO adjusts the weights to direct output towards the better ones amongst the group
-
-
Rough analogy:
-
If I perform a task once, I need a critic to say how well I do
-
If I perform it 10 times, I can compare the relative performances
-