Reasoning with Sampling: Your Base Model is Smarter Than You Think
- Reasoning with Sampling: Your Base Model is Smarter Than You Think
- 2025-10; Karan, Du
- GitHub: https://github.com/aakaran/reasoning-with-sampling/tree/main
High-Level Summary
- Capability vs Sampling:
- There is significant debate/interest in whether RL post-training develops new capabilities or just sharpens sampling
- If it's the latter, perhaps the distribution can be sharpened without any post-training
- Paper's contribution:
- Uses a Markov chain to sample from sharpened power distributions ( instead of , for some )
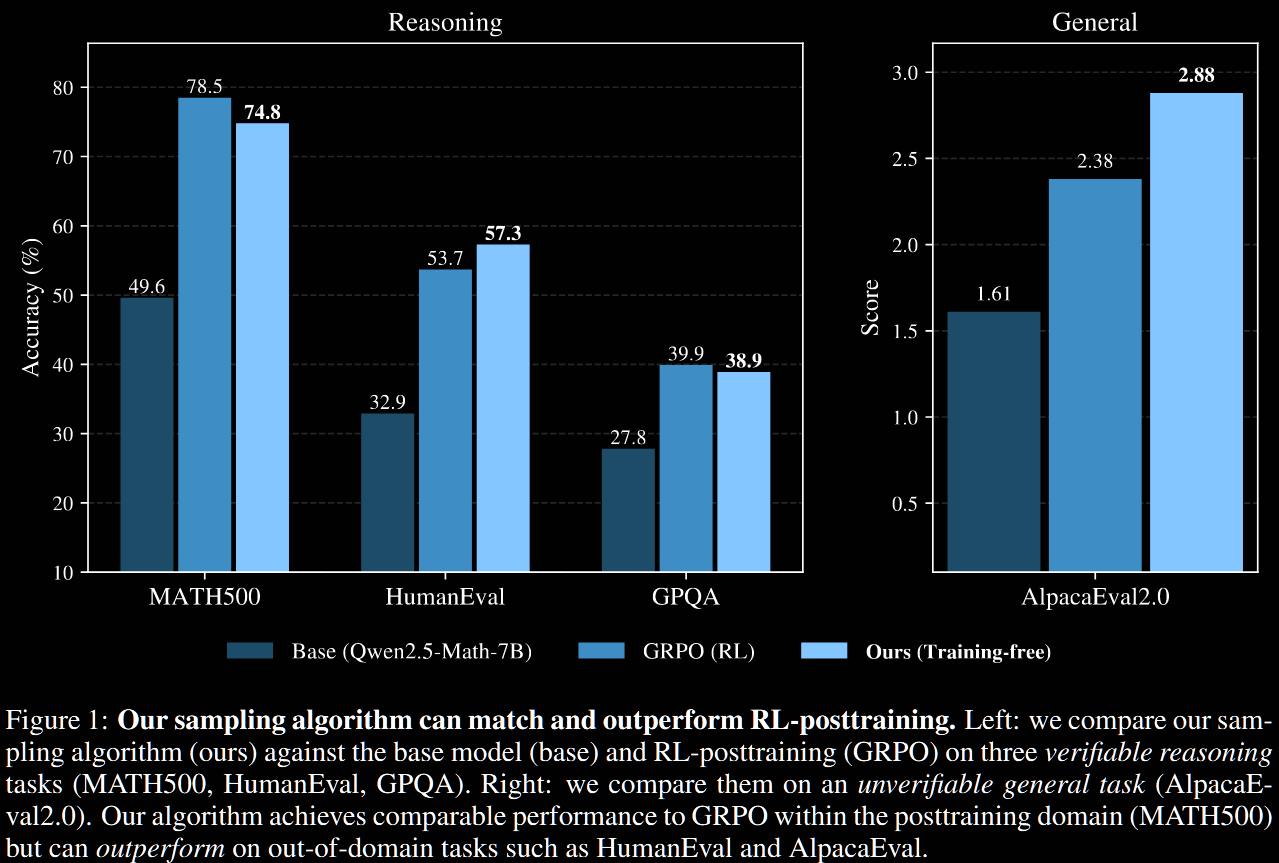
- Find substantial gains over base model and comparable with RL-post-trained versions
- No training, datasets, verifiers or the like are needed
Elevator Pitch
Post-training an LLM with RL often provides impressive improvements for pass@1, but pass@k decays for large . This raises the question, "Does RL develop new capabilities, or simply sharpen the distribution?" Eg, it may collapse to high-reward modes.
The current work achieves similar pass@1 performance increase by pure sampling, without RL. Moreover, pass@k remains competitive with the base even for up to .
Training LLMs to reason incentivises them to output their chain of thought (CoT). This allows exploration of different strategies, and backtracking, but comes at a significant computational cost: their CoTs can be very long, inflating the context length by an order of magnitude and more. This is expensive, both in terms of compute and latency, since it is serialised, not parallelised.
Contributions and Findings:
- sharpening distributions can match RL post-training
- sharpening can require expensive test-time compute
- performance boost appears to persist for larger pass@k
Methodology for Sharpening
Sharpening a distribution corresponds to reweighting it so that high-likelihood regions becomes even higher, whilst low-likelihood become even lower.
Power Distributions
The authors utilise power distributions:
given a distribution and real , the power distribution is defined such that for all .
Importantly, this is different to changing the temperature of the LLM sampler: where is the -power distribution and / is the -temperature distribution.
Intuitively, low-temperature sampling affects only the current token: it does not account for the likelihood of "future paths". Conversely, the power distribution up-weights the entire path. Naturally, sampling from exactly is computationally intractable—even calculating the normalising constant is. Instead, a Metropolis–Hastings algorithm is used.
Metropolis–Hastings
The authors use a standard Metropolis–Hastings (MH) algorithm. This draws approximate samples from a target distribution given only a proposal distribution . It is iterative:
- if , draw ;
- accept , setting , with probability where
- otherwise, reject , setting .
It is well known that the associated Markov chain converges to under mild conditions on .
Being able to evaluate is not necessary, only calculating ratios is; in particular, an unnormalised version can be used instead. Practically, both and should be easily computable—or, at least, their ratio.
The target distribution in the current set-up is ; the choice of is open. The following process is used:
given sequence , choose and resample the sequence starting at index using an LLM-proposal distribution .
The transition probabilities and are then simple to calculate. The flexibility of MH means that can be any LLM with any sampling strategy.
Power Sampling with MH
The Markov chain does converge to , but its mixing time—ie, the number of steps needed until its law is close to its target measure —may be large. The space is high dimensional, since we allow long sequences, so the mixing time could even be exponential in . For this reason, the proposed algorithm proceeds in blocks.
Fix a block size and proposal LLM . Let be the distribution given by , and consider the sequence of distributions We proceed inductively along .
To sample :
- initiate a MH algorithm by sampling (by induction);
- sample the next tokens with ;
- subsequence MH proposals resample from ;
- this is repeated for iterations.
The scaling is quantified by estimating the average number of tokens generated by this algorithm. Each candidate generation step when sampling resamples an average of tokens (approximately), and this is repeated times. Summing over gives There is a tradeoff between the block size and the number of Markov-chain steps .
Author note. Compute grows quadratically in the sequence length. So, the number of tokens used is not necessarily the most interesting proxy. If computing token in position takes units of compute, the expected amount of compute per step in iteration is Multiplying this by and summing over gives Conversely, the compute for direct, long-CoT sampling is
The Markov chain doesn't necessarily need to be that well mixed. Empirically, the authors find a value for that makes the algorithm work well for relatively small values of ; see the next section for details.
Author note. There appears to be some nested structure: to sample , first sample from and fix it; then, sample conditionally on . This could allow the MH proposal to resample from uniformly from . This would reduce the average number of resampled tokens from to , resulting in It's possible that a larger would be required, or potentially one that depends on with as .
Experiments
A standard suite of reasoning benchmarks is used: MATH500, HumanEval, GPQA-Diamond, AlpacaEval-2.0. Base models Qwen2.5-Math-7B, Qwen2.5-7B and Phi-3.5-mini-instruct are used.
Author note. The Qwen models may have been exposed to certain benchmarks during training. This could make them more amenable to sharpening methods—whether power-distribution sharpening or RL.
The following parameters are used.
- Maximum length ; early termination is possible with EOS token
- Split into 16 blocks, so , with steps
- Power-exponent with proposal LLM the base LLM with temperature
- For AlpacaEval 2.0, a slightly higher proposal temperature of improves performance
Main Results
The sharpened version achieves significant, "near-universal" boosts (as the paper puts it) in single-shot accuracies and scores across different reasoning and evaluation task versus the base algorithm. This includes +51.9% on Human Eval with Phi-3.5-mini and +25.2% on MATH500 with Qwen2.5-Math-7B. In particular, on MATH500, which is in-domain for RL post-training, power sampling achieves accuracies on par with those obtained by GRPO.
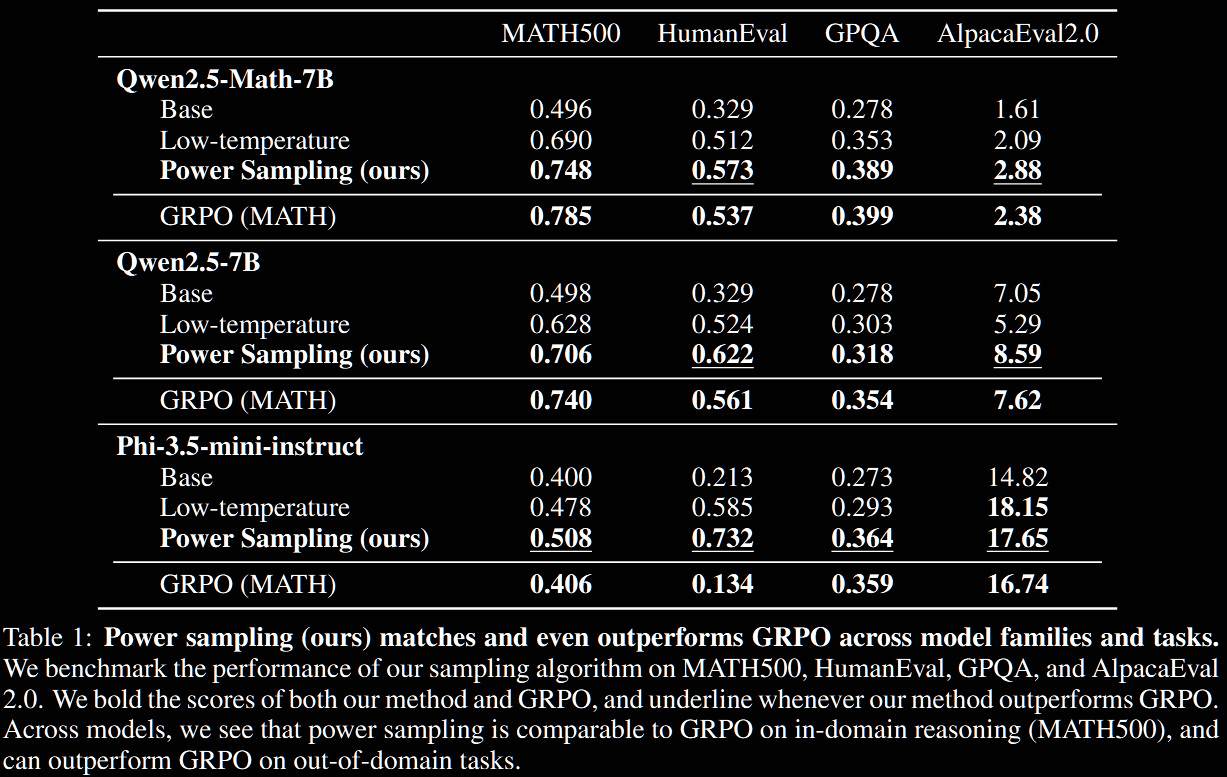
A defining, and arguably negative, feature of RL post-training is the long reasoning traces. On MATH500, Qwen2.5-Math-7B averages 600 tokens, whilst its GRPO version averages 671; surprisingly, power-sampling averages a similar 679 tokens without explicit encouragement.
Sampling vs Capability
The likelihoods/confidences of GRPO are more peaked and concentrated than for power sampling; see Figure 4, not repeated here. This suggests a collapse in diversity for GRPO not present in power sampling.
To quantify this, various pass@k metrics are plotted; Qwen2.5-Math-7B is used as the base model in the four plots below.
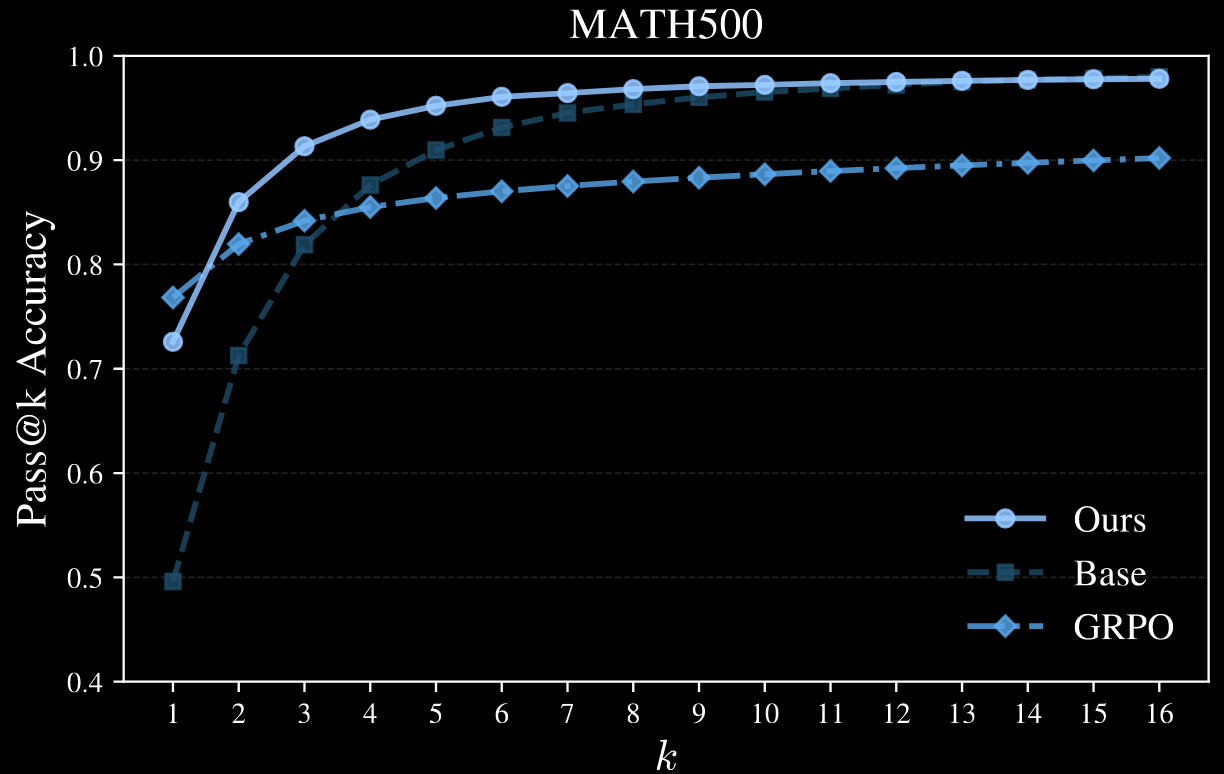
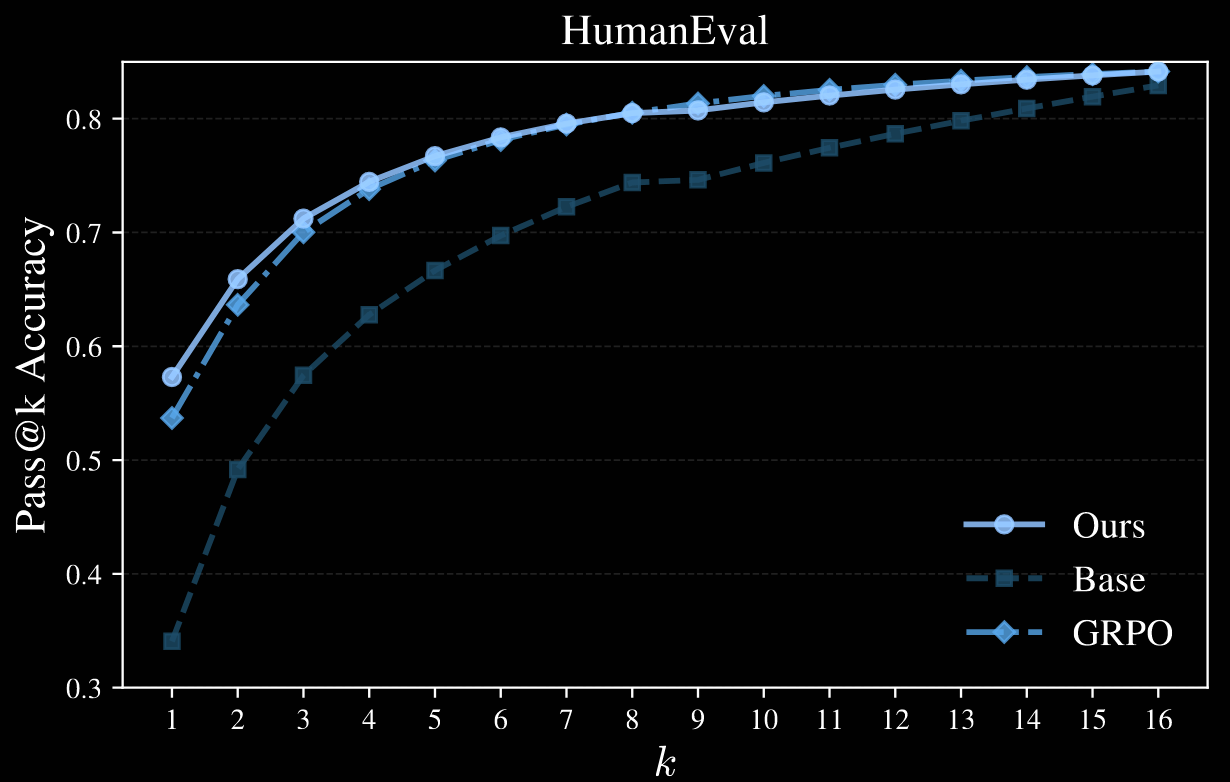
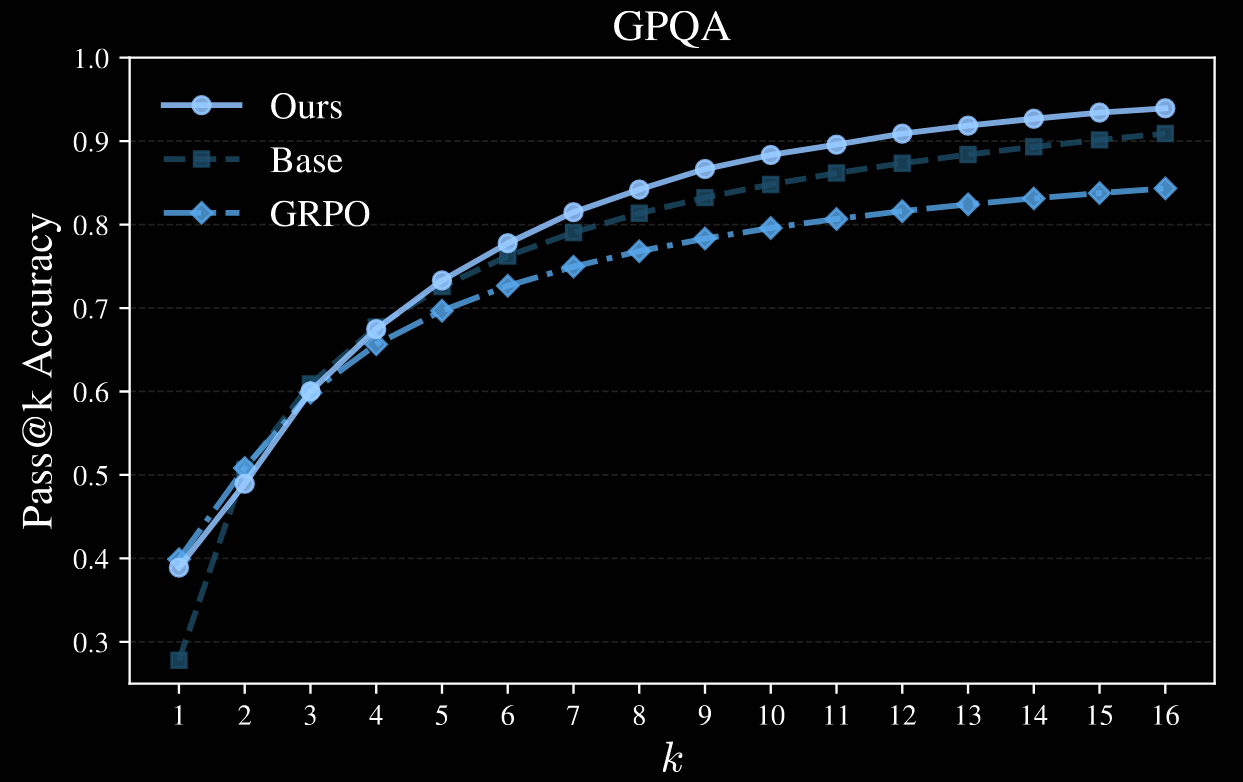
Author note. It's a shame the authors only went up to . This appears to be sufficient for MATH500, but higher values would certainly be interesting for HumanEval and GPQA; AlpacaEval is not plotted.
Exponent and Mixing-Time Hyperparameters
A light ablation on and is given.
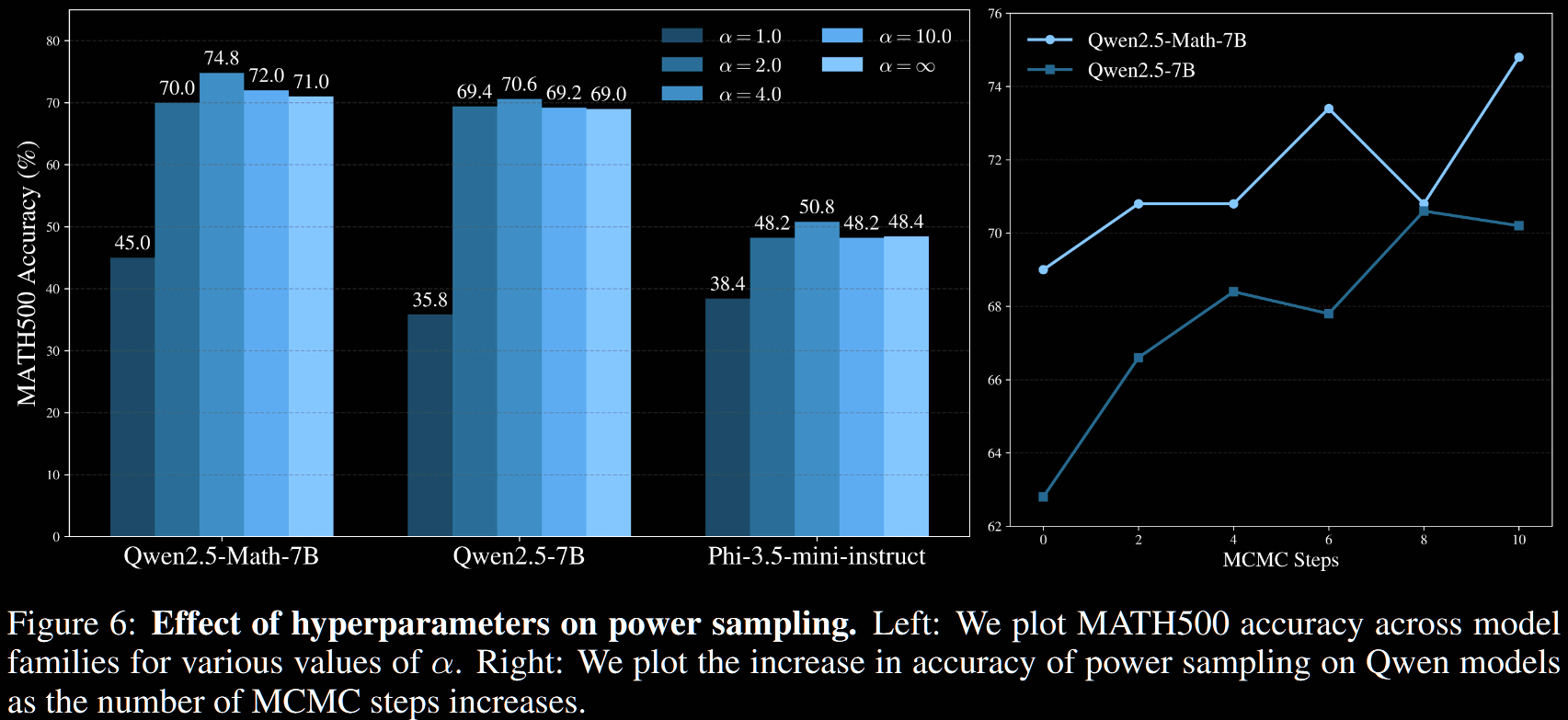
It is not plotted, but the authors claim that accuracy remained roughly stable for .
Test-Time Scaling
Using MH to approximate the power distribution at test time incurs test-time scaling costs vs standard, long-CoT inference:
- roughly times as many tokens;
- roughly times as much compute.
These factors are pretty close. Taking MATH500 on Qwen2.5-Math-7B as an example on which the average length is tokens, with and , In other words, about an extra order of magnitude of compute/tokens is required.
GRPO training typically uses 8–16 rollouts per sample, which is not so dissimilar. On the one hand, that may be run over many epochs, on larger datasets, requiring much more compute. On the other, once it's done, it's done, whilst power-sampling requires this every time it's used: it's a latency cost.
Conclusion
The paper makes a strong case for sharpening distributions. They nearly match performance on RL-post-trained systems for pass@1, but appear to avoid model collapse issues highlighted by deterioration in RL's pass@k performance for large .
It would be very interesting to investigate further sampling methods to really unlock base models' inherent capability.
Of course, the order-of-magnitude token/compute cost at inference is not ideal. More efficient methods would certainly be desirable.