ProRL Summary
- ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
- 2025-05; NVIDIA
High-Level Summary
- Introduces Nemotron-Research-Reasoning-Qwen-1.5B, a reasoning model based on DeepSeek-R1-1.5B
- Nemotron-1.5B outperforms its 1.5B base model, and even sometimes the DeepSeek-R1-7B
- Introduces ProRL, a prolonged RL training framework
- Argues that this allows the uncovering of novel reasoning strategies inaccessible to the base model
- Observed RL gain is larger when base model performs poorly, even increasing from ~0% base to ~100% after RL
Elevator Pitch
Recent advancements in reasoning have focused on RL-based fine-tuning. A fundamental question remains under debate:
Does RL truly unlock new reasoning capabilities, or does it merely optimise sampling of solutions already learned?
Several recent studies argue the latter, basing their conclusions on pass@ metrics with large . The authors of this paper argue the former, positing that the previous conclusions may stem from methodological constraints, not fundamental limitations of RL.
- Overreliance on specialised domains in which the models are often overtrained during both pre- and post-training, restricting potential for RL exploration.
- Premature termination of RL training prior to full exploration and development of new reasoning capabilities.
Methodology
The RL training is based on the GRPO algorithm, with a few tweaks to address entropy collapse. Entropy collapse, where the model's output becomes too concentrated early, causes the policy to commit to a narrow set of outputs prematurely, limiting exploration. This is particularly bad in GRPO, where the learning signal relies on having a diverse set of sampled outputs.
-
Decoupled Clipping.
In the original GRPO, the clipping is uniform. Here, the upper and lower thresholds are separated: , where is the observed policy ratio. Increasing further prompts the model to uplift probabilities of unlikely tokens which, nevertheless, provided significant advantage. They take (the default for in many libraries) but . This is pretty high: Magistral take , for comparison.
-
Token-Level Policy Gradient Loss.
GRPO employs a sample-level loss calculation: first, average the losses by token within each sample; then, aggregate the losses across samples. Notationally, . Each sample is assigned equal weight, and so tokens in longer responses are underweighted. DAPO uses a token-level calculation: .
These are taken from DAPO.
-
KL Regularisation and Reference-Policy Reset.
The original GRPO algorithm does include a KL penalty term , where is a fixed reference policy—typically the pre-RL model. Several recent papers, including Magistral and DAPO, removed this, arguing that the models naturally diverge from the reference policy anyway. As such, as training increases, the KL penalty may dominate the loss.
ProRL keeps the penalty term. To alleviate domination, the reference policy is hard-reset to a more recent snapshot periodically. (The hope is that) this allows continued improvement whilst maintaining the benefits of KL regularisation.
-
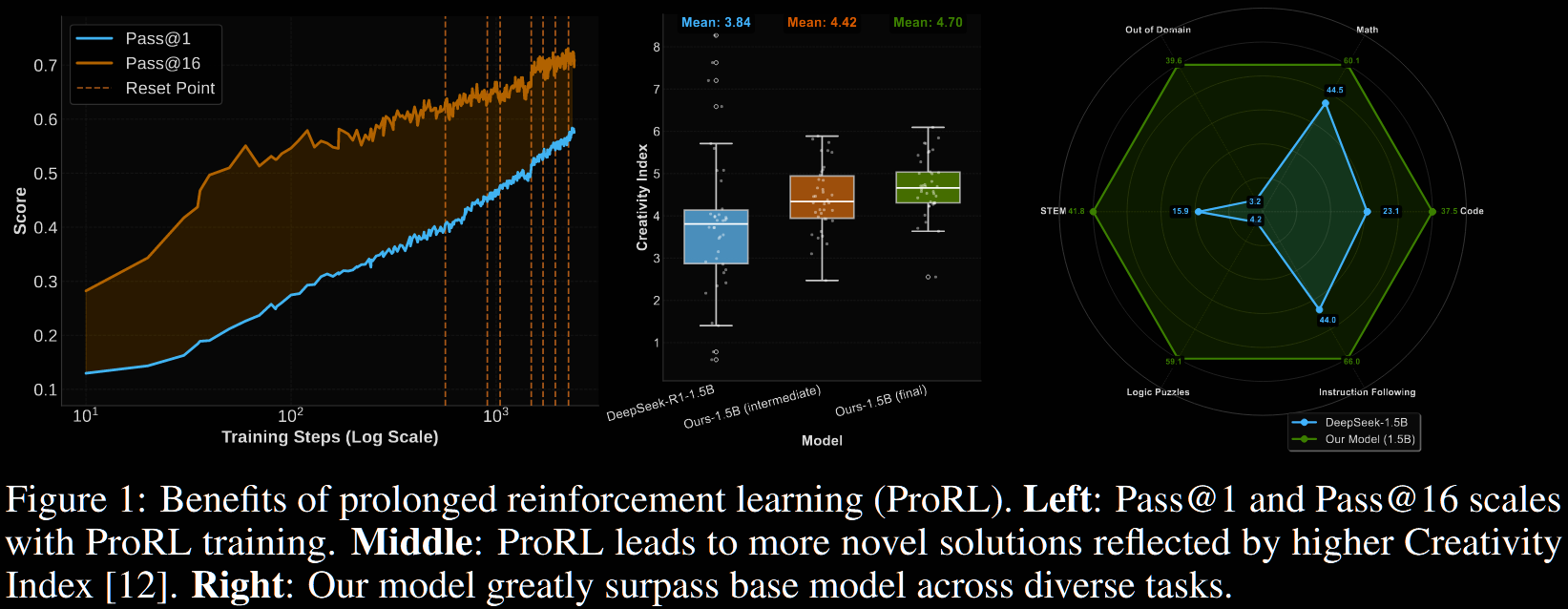
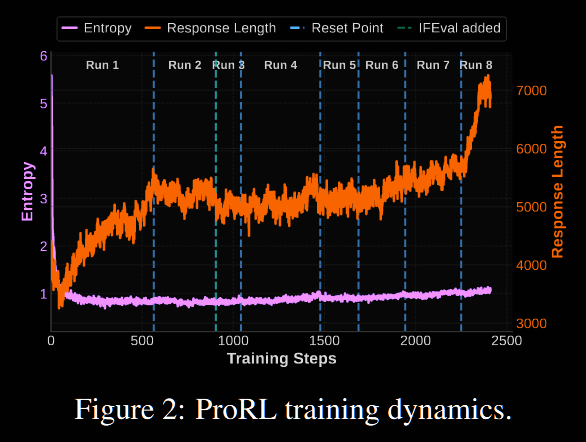
Prolonged RL.
Typically RL implementations run for no more than a few hundred steps. Contrastingly, ProRL demonstrated continued improvement beyond 2000 training steps; see Figure 1 (left) above. This gave the algorithm sufficient time to explore and uncover new strategies—so they hypothesise.
Results: Nemotron-Research-Reasoning-Qwen-1.5B
The result is, in their words, "the world's best 1.5B reasoning model"—and that is perhaps justified. In short, Nemotron-Research-Reasoning-Qwen-1.5B outperforms its baseline, DeepSeek-R1-Distill-Qwen-1.5B, by approximately
15% on maths and code, 25% on STEM reasoning, 22% on instruction following and >50% on text-based logic puzzles from Reasoning Gym.
It is comparable with, even outperforms, the much larger DeepSeek-R1-Distill-Qwen-7B.
It also outperforms the domain-specialised baselines of DeepScaleR-1.5B and DeepCoder-1.5B on maths and code, respectively, by around 5%.
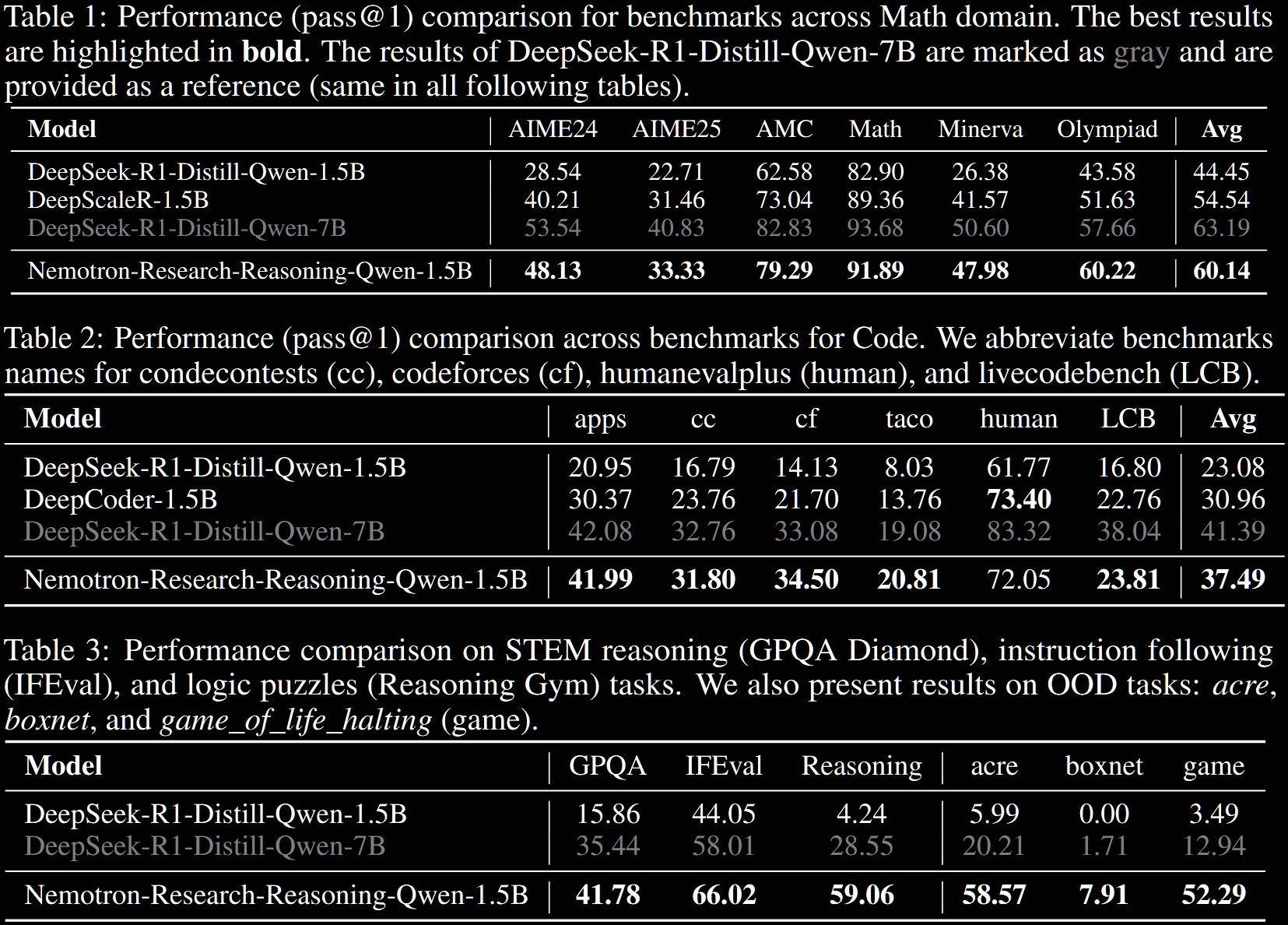
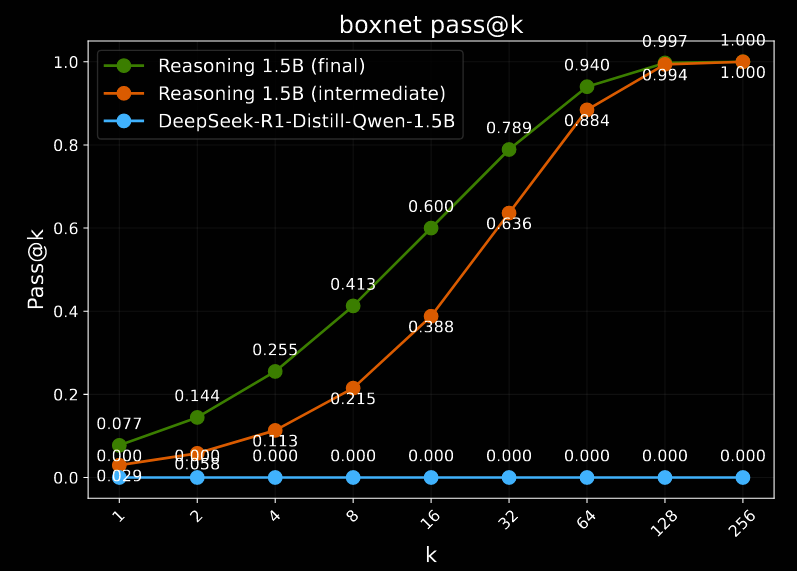
The subcategories in the "Reasoning [Gym]" benchmark are detailed in Table 5 in §F.1. The final three benchmarks in Table 3 (ie, acre, boxnet and game) are out-of-distribution tasks: these were not included in the RL training data.
The training set-up used verl, with and (as mentioned above), alongside dynamic sampling for filtering too easy/hard questions. For each question, responses were sampled, with a (high) sampling temperature of and response length capped at 8k tokens "to maintain concise and stable generations". Evaluation used vllm with a sampling temperature of and a maximum response length of 32k.
A context window limit of 8k was used throughout most of the training, until the final stage (~200 steps) in which it was increased to 16k tokens. It was observed that the model adapted quickly, with a noticeable increase in response length.
The dataset consisted of 136k examples. On 4 8xH100-80GB boxes, the whole training took approximately 16k GPU hours. The training dataset and recipe are detailed in §D and §E, respectively.
Analysis: Does ProRL Elicit New Reasoning Patterns?
The above evaluation is the usual benchmarking. It doesn't address the question of "enhance capabilities vs improve sampling". To address this, the results of pass@ are plotted as a function of , from to . Additionally, the final Nemotron model (green) is compared with an intermediary checkpoint (orange) as well as the base model (blue).
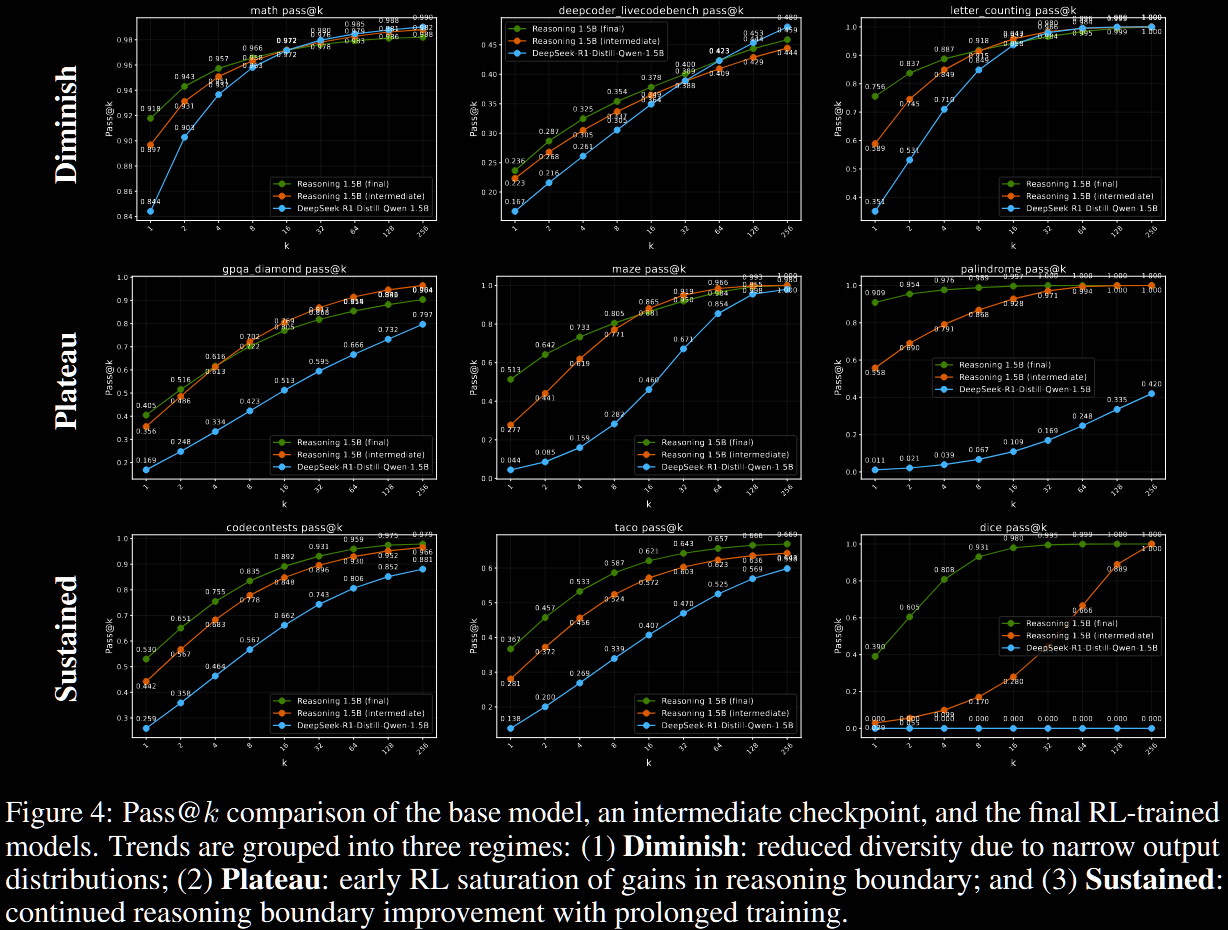
Many more examples are plotted in §F.2.
-
Diminished Reasoning Boundary
Nemotron exhibits decreased or unchanged reasoning capacity on some benchmarks (particularly in maths): pass@1 improves, but pass@128, which reflects broader reasoning abilities over sampling efficiency, often declines. These tend to have a high baseline pass@128, suggesting the base model already possesses sufficient reasoning ability, and the RL training sharpens the output distribution at the expense of exploration and generality.
-
Gains Plateau with RL
For these tasks, RL boosts both pass@1 and pass@128, indicating improved reasoning (not just sampling). However, these were largely achieved early in the RL training, as seen by comparing with the intermediate checkpoint.
-
Sustained Gains from ProRL
Some benchmarks, particularly more complex ones such as coding, show continued improvement—final vs intermediate. Although, the improvement at the high end (pass@128 or pass@256) is often small, indicated that the prolonged nature may help the sampling efficiency primarily (low end).
Generally, it was found that the RL-derived improvement was significantly negatively correlated with the baseline performance: little, or even negative, improvement was seen on tasks with a high baseline pass@128, but major improvements when the baseline was poor (even ~0% → ~100%).
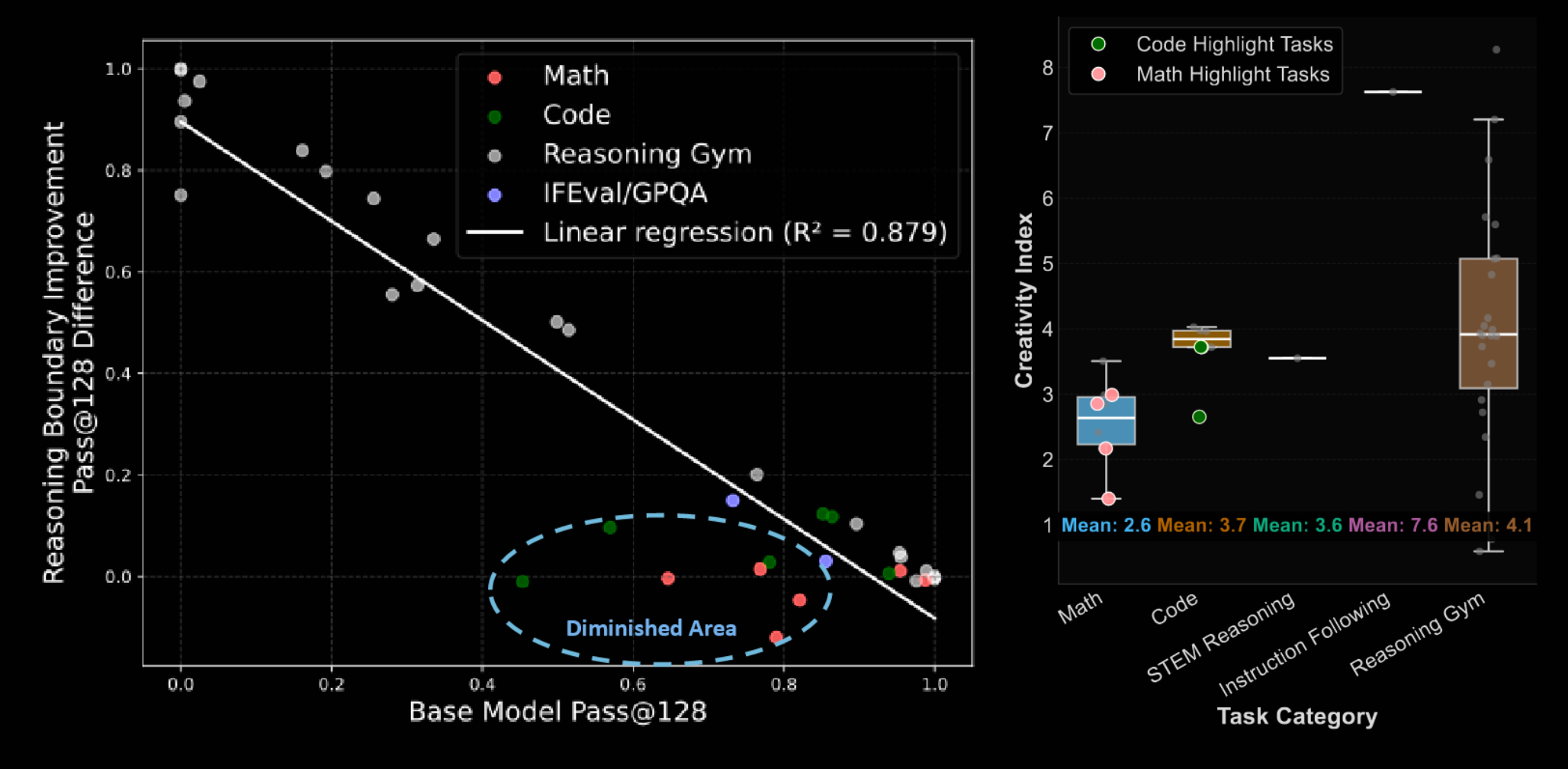
The tasks highlighted in the circle tend to have a low creativity index, indicating a higher overlap with pre-training data, suggesting the model has already seen a lot of similar data during training.
The last aspect we discuss is the out-of-distribution reasoning, which ProRL appears to enhance.
-
On boxnet, which was not seen during RL training, the base model is unable to solve the task. In contrast, with enough samples, ProRL is (almost) perfect—this is seen by both the final and intermediate versions, though.
-
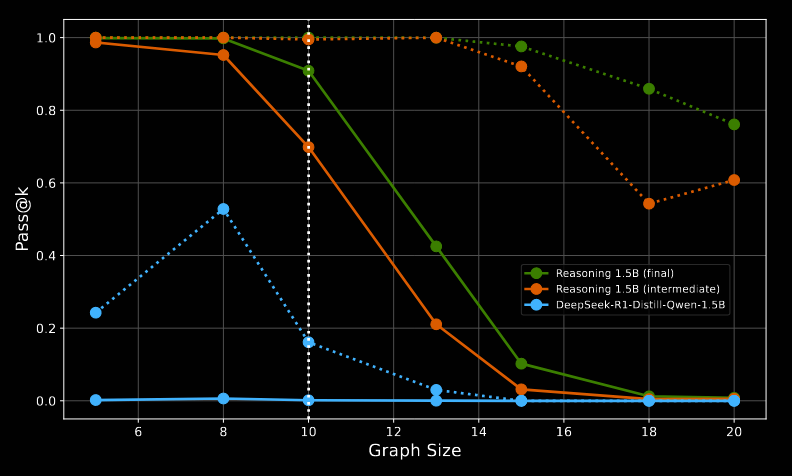
For graph_color, training data included only graphs of size 10. The pass@1 (solid lines) for both the baseline and Nemotron deteriorate with graph size, but pass@128 (dotted) persists for significantly longer for Nemotron versus the baseline.