Thinking on the Fly: Test-Time Reasoning Enhancement via Latent Thought Policy Optimization
- Thinking on the Fly: Test-Time Reasoning Enhancement via Latent Thought Policy Optimization
- 2025-10; Wengao Ye, Yan Liang, Shan
High-Level Summary
- Latent Thought Policy Optimization (LTPO):
- Initialise latent thought to append to prompt
- Use RL based on intrinsic confidence reward to adjust
- Parameter-free - LLM is frozen, RL only touches not the LLM
- Performance of LTPO:
- Matches or exceeds multiple baselines
- Significant speed-up vs CoT on complex problems (eg, ~50% on AIME)
Elevator Pitch
Chain of thought (CoT) was pretty revolutionary, but has many issues - perhaps foremost, its cost/latency. Recently, focus has shifted from text-based to latent reasoning. However, these often struggle on challenging, OOD tasks - those in which robust reasoning is most valuable.
Enter Latent Thought Policy Optimization (LTPO):
- a (fixed-size) 'latent thought' is initialised randomly;
- RL, with a confidence-based reward, is used to optimise this .
No training of the LLM is needed. In fact, AR decoding isn't even needed for the reward. This makes each RL step rapid.
Performance-wise, LTPO frequently matches full COT for the models studied (typically order 10B) for accuracy, yet is much faster on more challenging questions.
Method
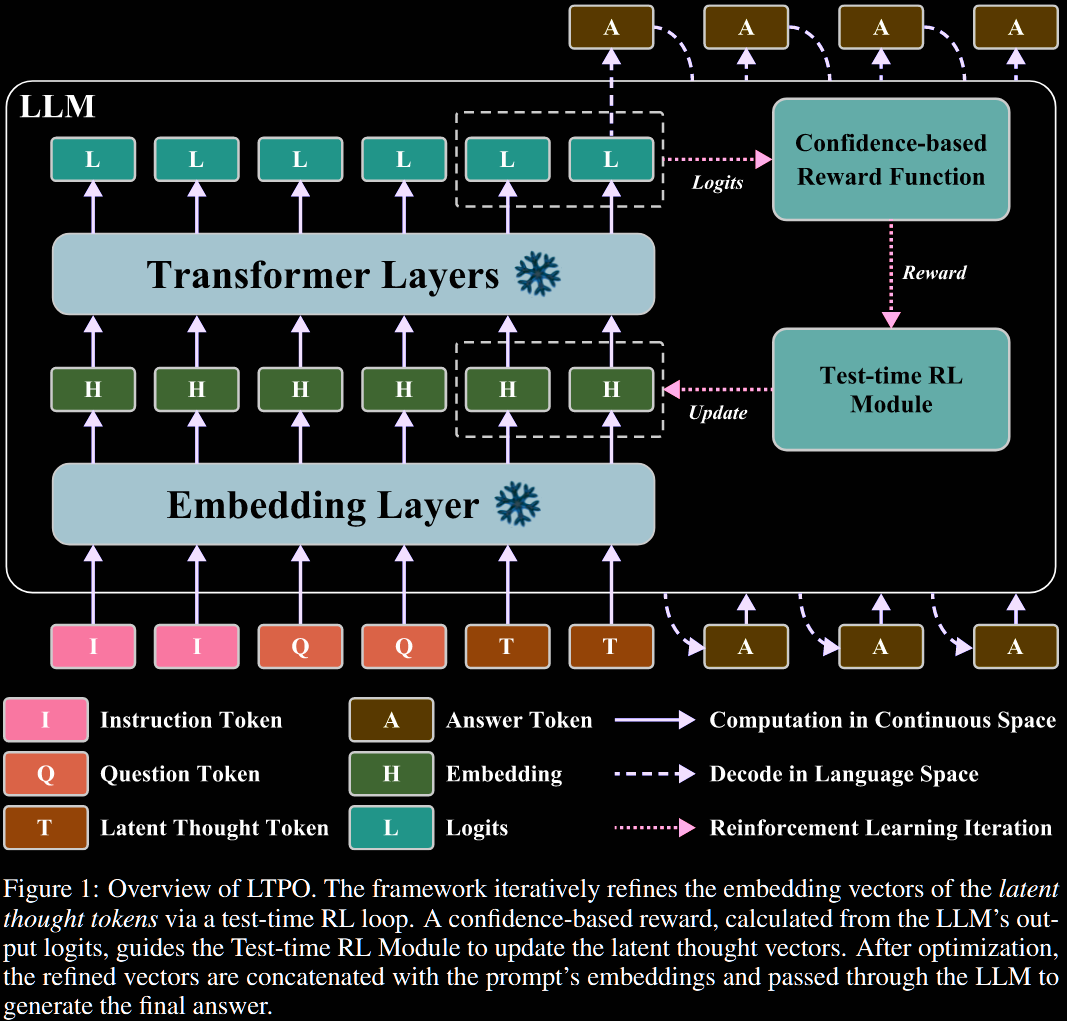
Let denote the frozen LLM, and its embedding layer. To enable latent reasoning, the embedded prompt is concatenated with placeholder latent thought tokens, denoted and initialised as It is that is optimised at test time by RL.
- State - the state is that of the latent thought tokens .
- Action - an action is a candidate for the next state of latent thoughts; it is not the increment. The action space is continuous.
- Policy - a simple Gaussian policy centred at the current state : the hyperparameter controls exploration, and is decayed over time.
- Reward - an intrinsic, confidence-based reward: the average of the top log probs, for a hyperparameter .
The latent thoughts are updated through the policy gradient. The reward function chosen is non-differentiable, so REINFORCE is used instead of standard backprop: But, . Taking the gradient, writing as before. The authors then use a single sample to estimate the gradient: leading to a 'gradient-ascent' update of where is the learning rate. To emphasise, this is a noisy estimate of gradient ascent.
After optimisation steps, the optimised latent thought vectors are concatenated with the prompt embeddings and passed through the AR LLM:
We point out that this gradient estimate uses no baseline. This will, no doubt, lead to very high variance estimators. It is a natural place to use GRPO.
Sample and set for , independently. The gradient update becomes where
Each requires a forward pass through the frozen LLM, so can be batched. It's more compute per optimisation step, but likely far more efficient.
Currently, their method is framed as RL, but it's really just random search that just happens to use the REINFORCE estimator.
Experiments
LTPO is compared against three baselines.
- Zero-Shot CoT
- the standard, discrete-space CoT, instructing the model to generate explicit, step-by-step thinking. In a variant, untuned
[UNK]tokens are appended: "[t]his baseline isolates the contribution of our test-time optimization procedure for latent thought tokens."
- the standard, discrete-space CoT, instructing the model to generate explicit, step-by-step thinking. In a variant, untuned
- SoftCoT performs reasoning in the continuous, latent space. It outperforms Coconut in certain cases, for example.
- LatentSeek applies test-time optimisation; unlike LTPO, it uses full AR decoding to evaluate intermediate steps.
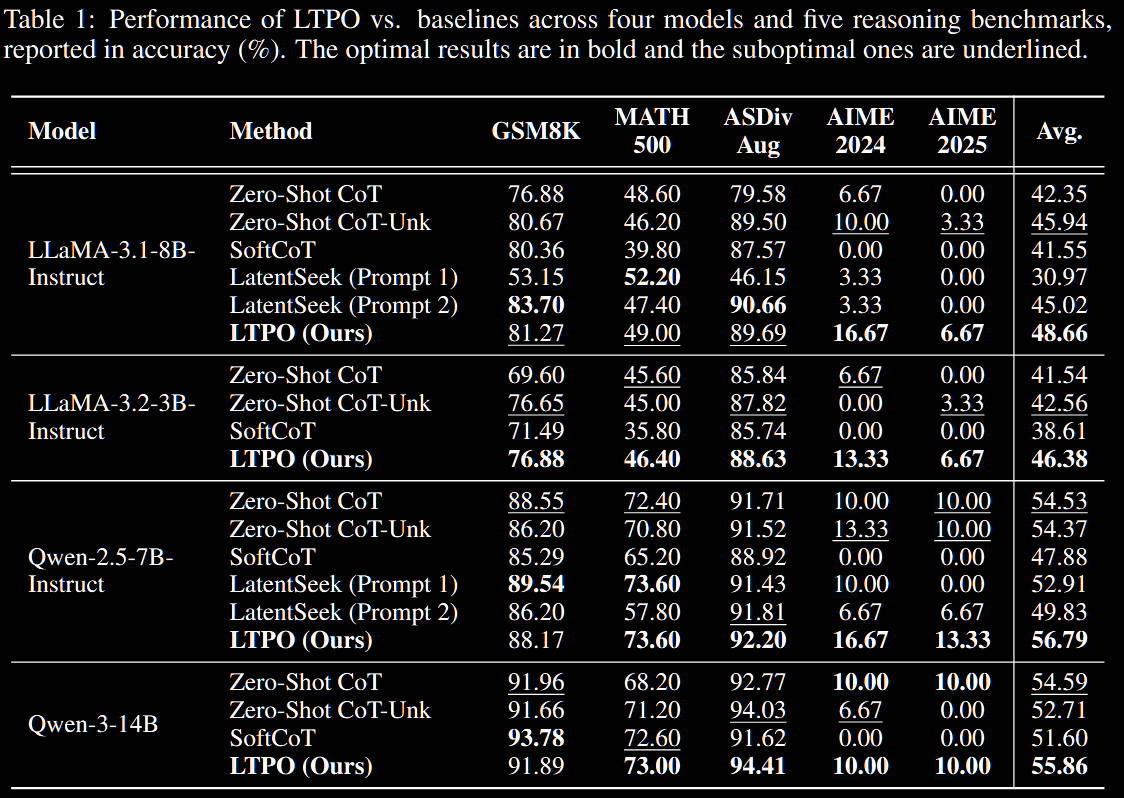
Further experiments are conducted and comparisons in the §4 of the paper, not reported here, including the following.
- Impact of number of thought tokens
- Inference efficiency
- (In)sensitivity to top- reward hyperparameter
- Generalisation to other domains
- Scalability with extended generation length
Conclusion
The paper decouples generation of latent reasoning from the LLM - which was trained on discrete tokens. Instead, the latent thought vectors are optimised directly at test time, via RL.
Getting a good reward signal at test time is the real challenge. They use an internal confidence-based reward, in essence aiming to sharpen the distribution. This definition is somewhat ad hoc, and certainly leaves open research into a better reward.
Overall, the paper is written well, with the experiments clearly laid out.