LLMs Are Singled-Threaded Reasoners: Demystifying the Working Mechanisms of Soft Thinking
- LLMs Are Singled-Threaded Reasoners: Demystifying the Working Mechanisms of Soft Thinking
- 2025-08; Chünhung Wu, Jinliang Lu, Zixuan Ren, Gangqiang Hu, Zhi Wu, Dai Dai, Hua Wu
High-Level Summary
- Latent reasoning ('soft thinking') became a hot topic in 2025
- What: replace discretely sampled tokens with continuous hidden layers or output probabilities
- Hope: these cts tokens are more 'information dense', and allow 'fluid'/'soft' reasoning over abstract concepts
- Claim: able to explore multiple reasoning paths in parallel, not restricted by early token sampling
- This paper explores inner workings of Soft Thinking:
- LLMs with soft thinking predominantly rely on the highest-probability part of their soft input
- This pushes them more towards greedy sampling than away from it
- Authors use Gumbel Softmax Trick to circumnavigate this "greedy pitfall"
Elevator Pitch
Latent reasoning has taken off recently - "reason over concepts not language", "explore multiple paths simultaneously", "reflects human thinking", etc. Performance gains are often reported but, for the training-free approaches particularly, the improvements are typically minimal. Moreover, they are often not robust, helping on some benchmarks and hindering on others - with no discernable (or, discerned) reason.
The current work dives deep into Soft Thinking:
- in short, average over the token distribution instead of sampling;
- see my summary or the original paper for details.
They provide evidence against the claim of increased diversity and parallel reasoning; their evidence suggests LLMs are single-threaded reasoners, and soft thinking actually makes the sampling more greedy, with paths stemming from the non-top token typically terminated in a couple of steps.
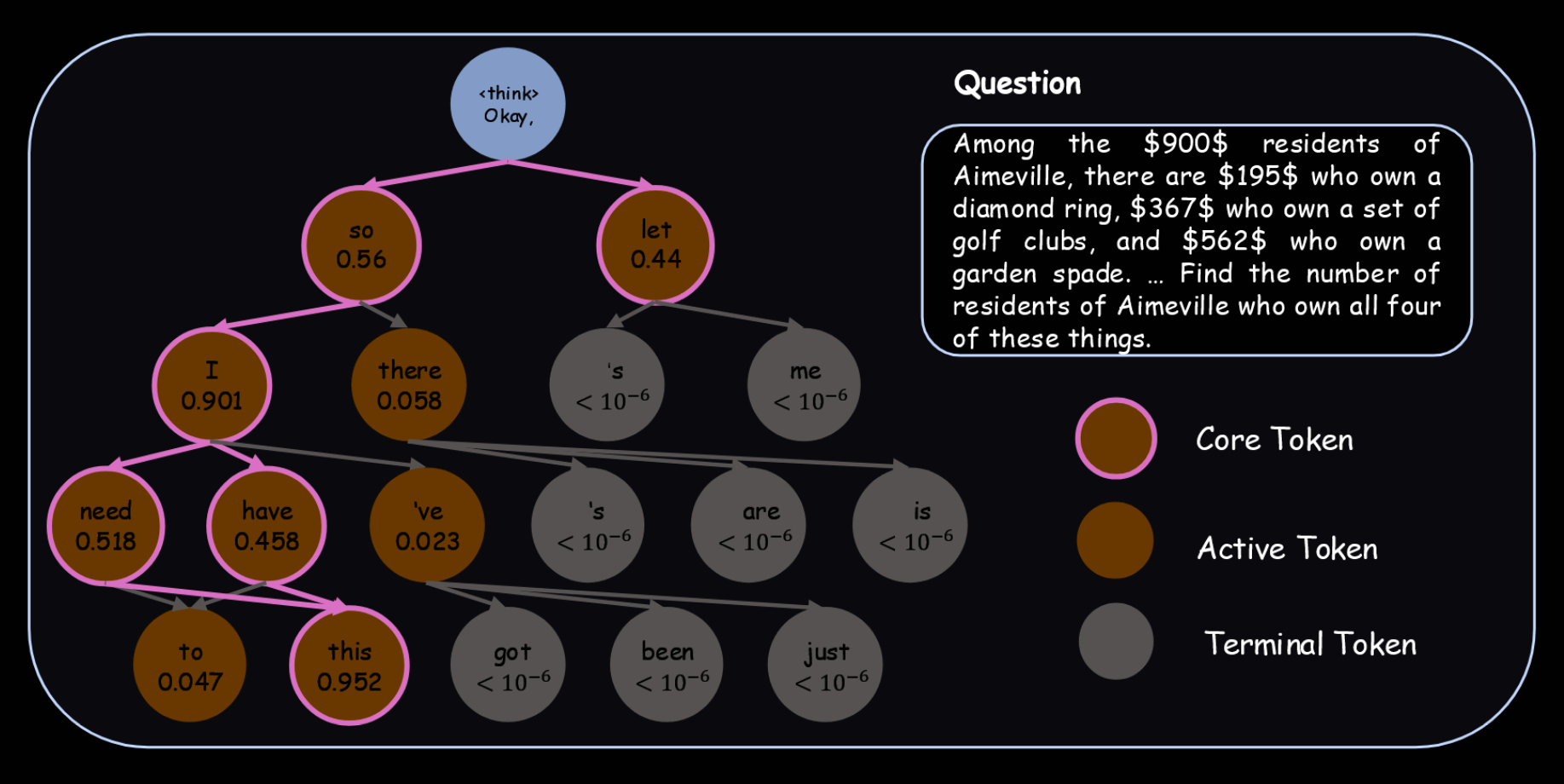
The authors suggest reintroducing randomness via the Gumbel softmax trick - actually, a pretty smart application of it.
Background
The Soft Thinking framework is briefly and informally described here; see my summary or the original paper for more details.
Given an input and generated tokens , the LLM predicts the next token :
where is the vocabulary and the simplex. The (embedding of the) soft token is defined as the expectation
where is the embedding of token , the -th in the vocabulary . Typically, a top-{/} truncation (and renormalisation) is used.
The paper conflates the distribution and expectation frequently, but without causing significant confusion.
Investigation
Experimental Results
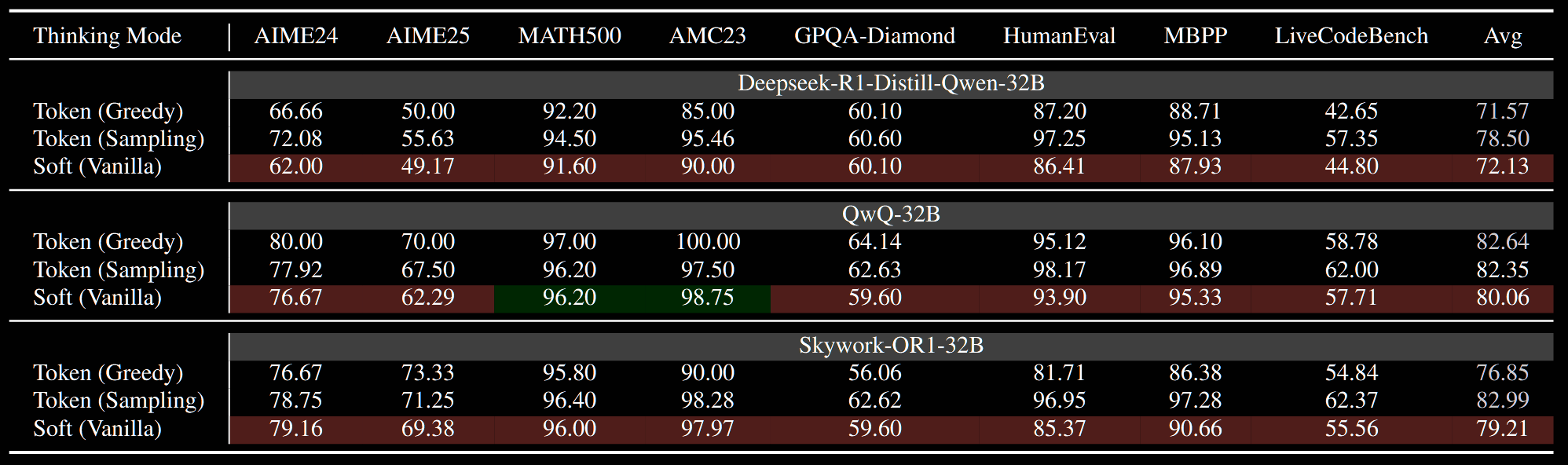
Soft Thinking is evaluated across seven benchmarks and three 32B models (DeepSeek-R1-Distill-Qwen-32B, QwQ-32B and Skywork-OR1-32B), with generation length capped at 32,768 tokens. The authors find that, almost universally, Soft Thinking performs worse than traditional sampling—and even performs worse than greedy 'sampling', in which the top token is chosen deterministically.
Case Study
There is certainly some evidence that Soft Thinking actually behaves in a pretty greedy manner. Instead of spreading out the distribution, it actually focuses it on the high-probability paths. This is really counter to the narrative pushed by those advocating for such approaches. The following figure shows top 95% of tokens (I think). Invariably, they exhibit semantic coherence only with the dominant token from the previous step:
- in steps 2 & 3, the word "I" does not make sense after "let";
- the words in step 44 are capitalised, suggesting they only follow the fullstop in step 43.
This leads the authors to hypothesis:
- LLMs lack the ability to process multiple different semantic trajectories in parallel;
- when a soft token is fed in, the generation process is typically dominated by the majority component of that soft token.
They evidence this further with analysis of the Jensen–Shannon (JS) divergence between probability distributions; see their §4.2 for more details.
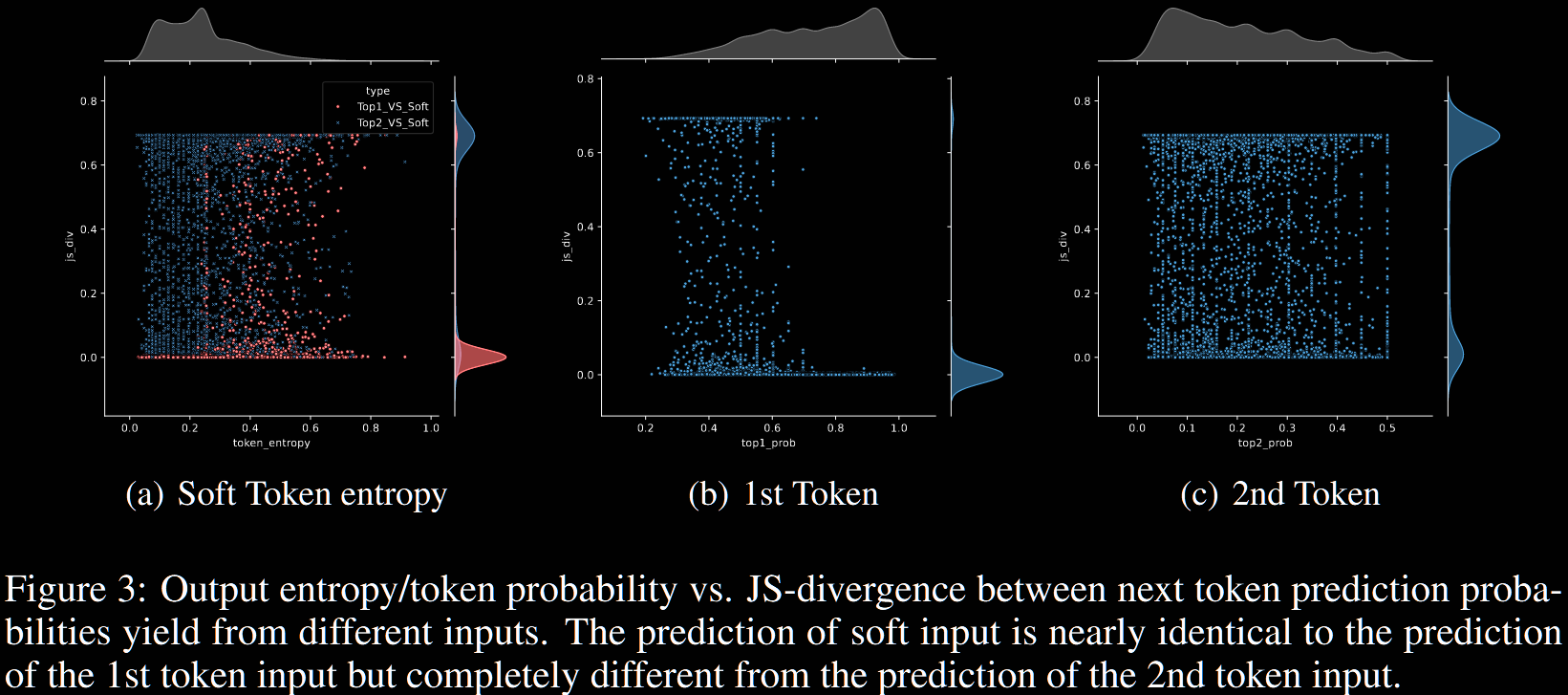
The authors refer to this greedy-like behaviour as the greedy pitfall.
Mixture of Inputs
A related method is Mixture of Inputs (MoI). This randomises the probability distribution by sampling a token and taking a mixture of the one-hot encoded sampled token and the soft token (expectation).
However, whilst MoI isn't references in the current paper, it only makes the probability distribution more concentrated around its top token. So, it seems likely that MoI suffers from similar issues to vanilla Soft Thinking.
Addressing the Greedy Pitfall
The key aspect is to use randomised soft thinking. The authors consider Dirichlet Sampling and the Gumbel Softmax trick; for simplicity, we focus on the latter here. The key idea is to add noise to the logits :
instead of sampling according to , use where , the unit Gumbel distribution.
The reason for using the Gumbel distribution is the following invariance. Let / denote the usual/Gumbel softmax; ie, and , which is a random variable. Then, averaging over the Gumbel noise,
[Author note: I haven't checked this myself, but presumably it isn't difficult. The result is cited in this paper, and dates back to 2017.]
So, from a sampling point of view, nothing has changed. But, from a soft thinking point of view, we now have a new, randomised probability distribution.
This addresses the greedy collapse. Consider Figure 1, in which both "so" and "let" receive significant probability mass: 56% and 44% respectively. The higher-weighted "so" dominates in that figure, but if they get Gumbel noise, it's reasonably likely the noisy version of "let" is then the higher-weighted. This enables exploration of many more paths.
The table below demonstrates improved performance, particularly for the Gumbel variant, of randomised Soft Thinking over both vanilla Soft Thinking and vanilla sampling.
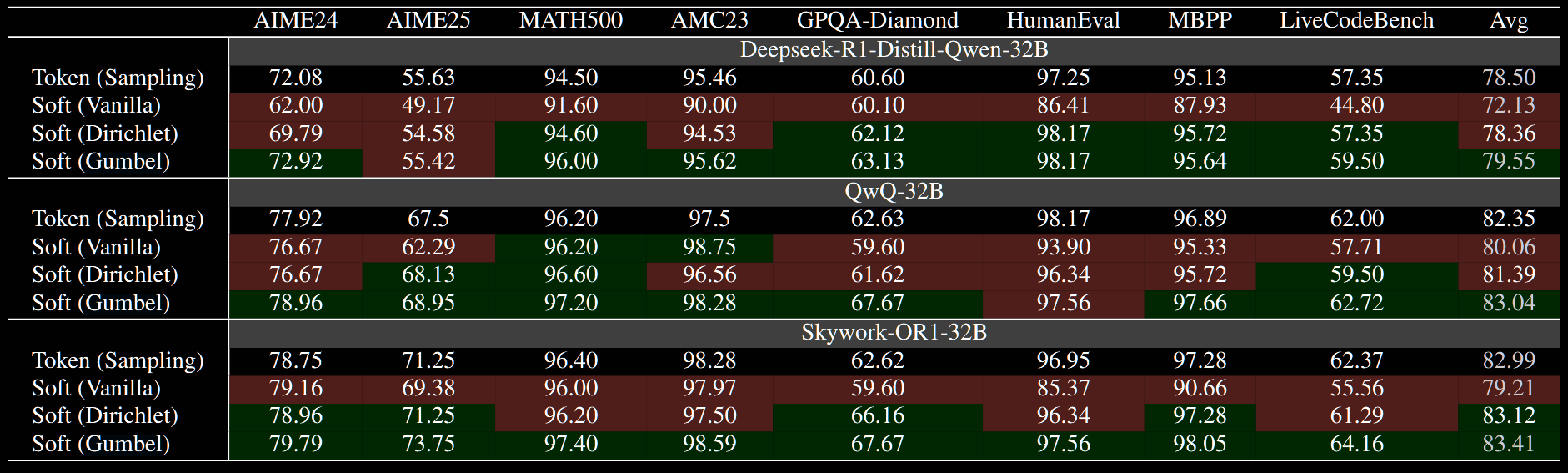
The paper isn't definitive, but it seems that *the same temperature is used across all nine benchmarks; the temperature isn't fitted to the specific benchmark.
The authors also discuss balancing softness and randomness. The objectives of this section are less well-defined to me, and I'm not really sure what they're trying to get at. They conclude that Gumbel balances these two better than Dirichlet though; it also performs better in the above table.
Conclusion
The paper makes a strong case for issues surrounding vanilla soft thinking. Their Gumbel-softmax randomisation strategy has much better theoretical grounding and, for example, that used in Mixture of Inputs.
After all the discussion and examples around how vanilla soft thinking has collapse issues, no investigation is given for their randomised versions. Improved performance is demonstrated, suggesting some issues have been resolved. But, a proper investigation is unfortunately missing.
A cynic would suggest that such an investigation is so obviously needed that it's lack of inclusion suggests results did not align with their expectations or desires.