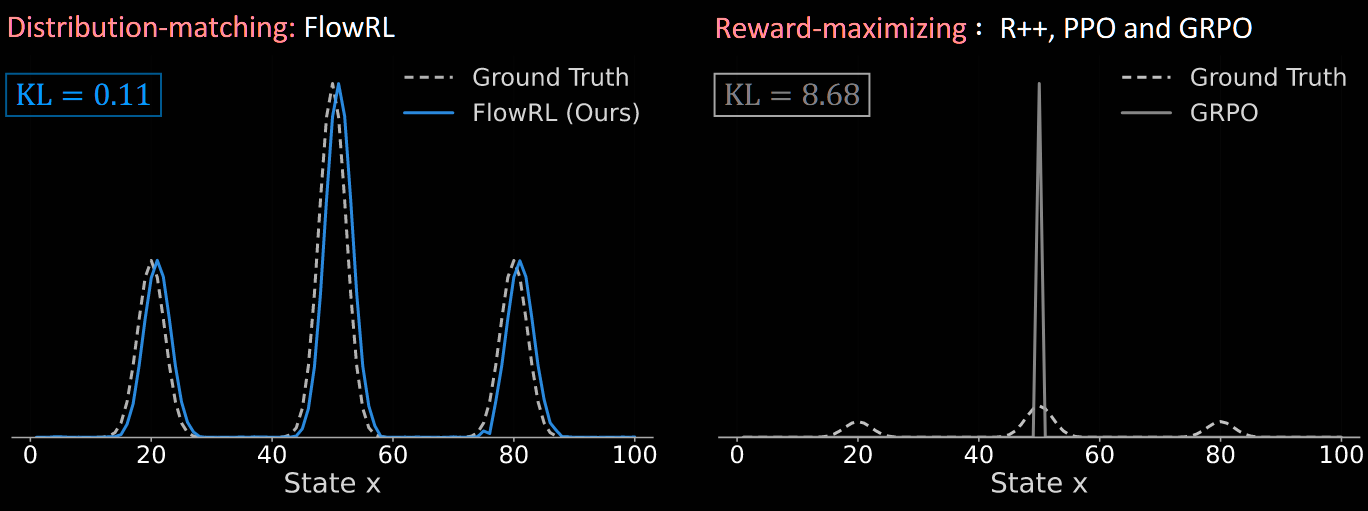
Most algorithms (eg, PPO or GRPO and its variants) aim purely to maximise rewards
FlowRL matches the policy to the full reward distribution
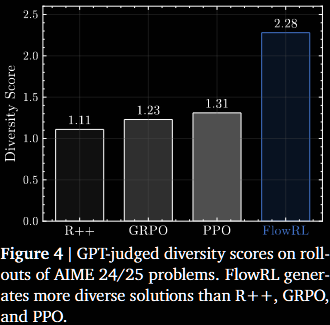
Argues that this explicitly promotes diverse exploration and generalisable reasoning trajectories
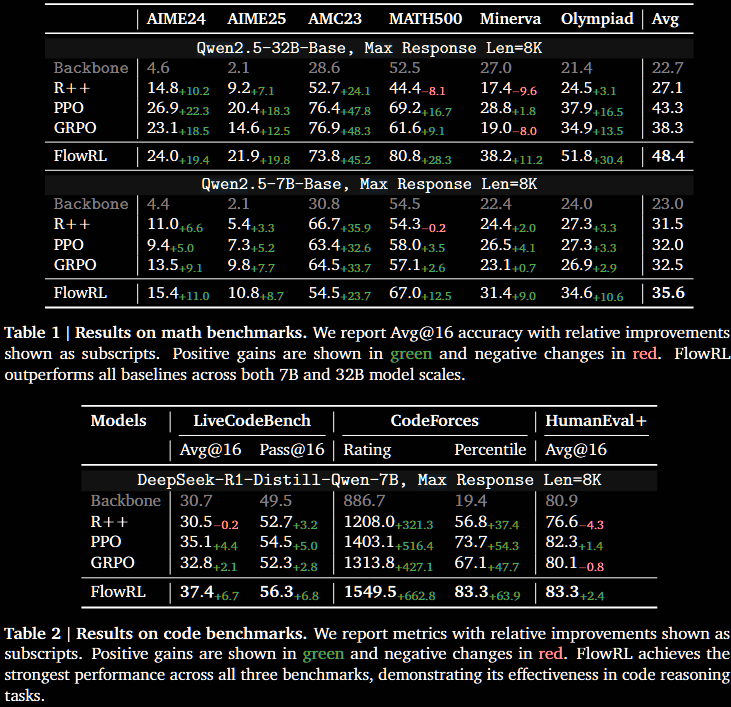
Pros: observed improvements for FlowRL vs PPO/GRPO/REINFORCE++:
better scores on maths/code benchmarks
more diverse reasoning traces, sometimes significantly
Cons: no comparison with more recent GRPO variants which also promote diversity
Code is available on GitHub, based on verl: FlowRL
Elevator Pitch
Mainstream reasoning LLMs are trained with reward-maximising RL methods. These tend to overfit to the dominant reward signal, neglecting all other reasoning paths—model collapse. Such other paths have a lower reward, but may still be valid—eg, simply longer or less elegant. FlowRL aims to minimise the (reverse) KL divergence between the LLM's policy πθ(y∣x) and a target distribution ∝eβr(x,y), where r(x,y) is the reward for answering y to question x.
The evaluation focusses on maths/code benchmarks and LLM-judged diversity of responses. Improvements in both are observed vs GRPO and PPO. However, it must be noted that there are many variants of GRPO explicitly designed to address diversity issues, such as DAPO, ProRL or GSPO/GMPO.
Methodology
Reward Maximisation to Distribution Matching
The objective is to minimise a (reverse) KL divergence between the LLM's policy and a target distribution. Inspired by energy-based modelling, which comes from statistical physics, the target is a Gibbs measure given question x:
eβr(x,y)/Z(x), where r(x,y) is the reward, β the inverse temperature and Z(x) the partition function.
As always, the partition function is intractable; it is thus parametrised (Z=Zϕ) and learned. The objective is then to minimise
θminEX∼q[KL(πθ(⋅∣X)∥eβr(x,y)/Zϕ(x))],(⋆)
where q is a distribution over potential questions. (The expectation over x is my assumption: it is not explained in the paper.)
This KL objective is approached via the framework of GFlowNets.
GFlowNets: brief summary.
Paraphrasing §2, GFlowNets are a probabilistic framework for training stochastic policies to sample discrete, compositional objects (eg, graphs or sequences) in proportion to a given reward. The core principle is to balance forward and backward probability flows at each state, inspired by flow matching (Bengio et al, 2021).
The technical observation (not knew to FlowRL) is that, in terms of expected gradients, minimising the KL objective in (⋆) is equivalent to minimising the trajectory balance (TB) loss in GFlowNets. It is stated informally and non-rigorously in the FlowRL paper.
Proposition 1 (informal). In terms of expected gradients, minimising the KL objective in (⋆) is equivalent to minimising the TB loss used in GFlowNet:
θminstandard KL divergenceKL(πθ(y∣x)∥eβr(x,y)/Zϕ(x))⟺θmintrajectory balance in GFlowNets(logZϕ(x)+logπθ(y∣x)−βr(x,y))2
Formally, this should be interpreted in the following way.
Proposition 1 (formal). For a question x and response y, denote the pointwise KL and TB losses as follows:
LθKL(x)Lθ,ϕTB(x,y):=KL(πθ(⋅∣x)∥eβr(x,⋅)/Z(x));:=(logπθ(y∣x)+logZϕ(x)−βr(x,y))2.
Then, the "expected TB gradient" equals the (full) KL gradient:
2∇θLθKL(x)=EY∼πθ(⋅∣x)[∇θLθ,ϕTB(x,y)].
In other words, to get an unbiased estimator of LθKL(x), sample Y∼πθ(⋅∣x) and compute ∇θLθ,ϕTB(x,Y).
Derivation of formal version of Proposition 1.
Define the KL and trajectory balance (TB) objectives (losses), pointwise wrt questions x:
LθKL(x)Lθ,ϕTB(x,y):=KL(πθ(⋅∣x)∥eβr(x,⋅)/Z(x));:=(logπθ(y∣x)+logZϕ(x)−βr(x,y))2.
Expanding the KL divergence,
LθKL(x)=EY∼πθ(⋅∣x)[log(πθ(Y∣x)Z(x)/eβr(x,Y))]=EY∼πθ(⋅∣x)[logπθ(Y∣x)+logZ(x)−βr(x,Y)].
The law of Y∼πθ(⋅∣x) depends on the parameters θ. Abbreviate
δθ(x,y):=logπθ(y∣x)+logZ(x)−βr(x,y),
which has
∇θδθ(x,y)=∇θlogπθ(y∣x).
Start with the KL term, using πθ(y∣x)∇θlogπθ(y∣x)=∇θπθ(y∣x) and ∑y∇θπθ(y∣x)=∇θ∑yπθ(y∣x)=∇θ1=0:
∇θLθKL(x)=∑y∇θ(πθ(y∣x)δθ(x,y))=∑y(∇θπθ(y∣x)⋅δθ(x,y)+πθ(y∣x)⋅∇θlogπθ(y∣x))=∑y∇θπθ(y∣x)⋅(δθ(x,y)+1)=∑y∇θπθ(y∣x)⋅δθ(x,y)=EY∼πθ(⋅∣x)[∇θlogπθ(Y∣x)⋅δθ(x,Y)].
This is the policy gradient form. Turning to the TB term, the derivative is taken before the expectation over y:
∇θLθ,ϕTB(x,y)=∇θδθ(x,y)2=2∇θlogπθ(y∣x)⋅δθ(x,y).
Hence,
2∇θLθKL(x)=2∇θEY∼πθ(⋅∣x)[δθ(x,Y)]=EY∼πθ(⋅∣x)[2∇θlogπθ(Y∣x)⋅δθ(x,Y)]=EY∼πθ(⋅∣x)[∇θLθ,ϕTB(x,Y)].
This squared-loss approach has a key advantage over direct KL optimisation: Zϕ(x) can be treated as a learnable parameter, rather than requiring explicit computation of the intractable partition function Z(x). Using a stable squared-loss form is also advantageous practically.
However, the actual value of Zϕ(x) has no effect on the expected gradients. Indeed,
∇θLθ,ϕTB(x,y)=∇θlogπθ(y∣x)⋅g(x,y;θ)whereg(x,y;θ):=logπθ(y∣x)+logZϕ(x)−βr(x,y).
But, EY∼πθ(⋅∣x)[∇θlogπθ(Y∣x)]=0. Hence, adding anything to g that is independent of θ does not affect
EY∼πθ(⋅∣x)[∇θLθ,ϕTB(x,y)].
That doesn't mean that Zϕ(x) should be ignored. Rather, it plays the same role as the baseline in standard RL training. The true partition function minimises the variance.
Learning Zφ: gradients and regression.
Looking back at the per-x KL objective, define
Lθ,ϕKL:=EY∼πθ(⋅∣x)[logπθ(Y∣x)+logZϕ(x)−βr(x,Y)];
then, Lθ,ϕKL=LθKL if Zϕ=Z.In order to minimise the variance, Zϕ(x) should be such that
logZϕ(x)=EY∼πθ(⋅∣x)[βr(x,Y)−logπθ(Y∣x)]=EY∼πθ(⋅∣x)[log(eβr(x,Y)/πθ(Y∣x))].
Interestingly, this is not the true partition function Z(x): indeed,
logZ(x)=logEY∼πθ(⋅∣x)[eβr(x,Y)/πθ(Y∣x)].
Calculating either exactly is intractable, so least-squares regression is used:
minimise(logZϕ(x)−βr(x,y)+logπθ(y∣x))2=Lθ,ϕTB(x,y)wrtϕ.
Taking derivative wrt ϕ,
∇ϕLθ,ϕTB=2(∇ϕlogZϕ(x)−βr(x,y)+logπθ(y∣x)).
Thus, the following update is used: sample y1,...,yN∼iidπθ(⋅∣x) and replace
logZϕ(x)←(1−η)logZϕ(x)+η⋅n1∑i=1N(β(r,yi)−logπθ(yi∣x)),
where η∈(0,1] is the learning rate.
Proposition 5 in Appendix B shows the optimisation problem in Proposition 1 is equivalent, in the same sense, to
θmax{EY∼πθ(⋅∣x)[βr(x,y)−logZϕ(x)]+H(πθ(⋅∣x))},
where H(μ):=−EX∼μ[logμ(X)] denotes the entropy of the distribution. So, the FlowRL objective can be interpreted as jointly maximising reward and entropy. This encourages the policy to cover the entire reward-weighted distribution, rather than collapsing to a few high-reward modes.
FlowRL
Proposition 1 is not new to FlowRL. However, its application to long context is new. Previous GFlowNets works typically operate on short trajectores in small, discrete spaces (no citation given). Long CoT reasoning introduces two challenges.
Exploding gradients. The log-probability term logπθ(y∣x) decomposes as ∑tlogπθ(yt∣y<t,x), causing the gradient to potentially scale with sequence length.
Sampling mismatch. Mainstream RL algorithms often perform micro-batch updates and reuse trajectories collected from an old policy, for efficiency reasons. Contrastingly, the KL-based trajectory balance (TB) objective assumes fully on-policy sampling, with responses drawn from the current policy.
Neither of these issues is new to RL post-training of LLMs. Exploding gradients are addressed by length normalisation, rescaling as
∣y∣1logπθ(y∣x)=logπθ(y∣x)1/∣y∣.
The sampling mismatch is handled with importance sampling in a relatively standard way, alongside some clipping:
w=clip(πθ(y∣x)/πθold(y∣x),1−ε,1+ε)detach,
where the subscript-"detatch" indactes that the gradient is detatched during its calculation.
Following established practices in the GFlowNets literature, a reference model is incorporated as a prior constraint on the reward distribution:
eβr(x,y)is replaced witheβr(x,y)⋅πref(y∣x).
Naturally, Z(x) should now be updated; although, as discussed above, its actual value doesn't affect the gradients, only the variance. This adjustment leads to the following minimisation problem:
θmin(logZϕ(x)+logπθ(y∣x)−βr(x,y)−logπref(y∣x)).
Additionally, as in GRPO, group normalisation is applied to r(x,y):
r^i=(ri−meanr)/stdr,
where r={r1,...,rG} denotes a set of rewards within a sampled group.
Substituting all this into Proposition 1 provides the following objective:
Lθ,ϕFlowRL(x,y):=w(logZϕ(x)+∣y∣1logπθ(y∣x)−βr^i(x,y)−∣y∣1logπref(y∣x))2.
Results
FlowRL is compared with fairly 'vanilla' RL algorithms: REINFORCE++ (2025/01), PPO (2017/07) and GRPO (2024/12). There are modern variants, or tweaks, of GRPO which explicitly address diversity, such as DAPO (2025/03) or ProRL (2025/05). Others, such as GSPO (2025/07) and GMPO (2025/07), address stability. It is highly disappointing that no comparison with these is done—especially as multiple are mentioned in the paper. At least relatively large models are used: 7B and 32B.
Nevertheless, the reported results are included below, for completeness.