Controlling Thinking Speed in Reasoning Models
- Controlling Thinking Speed in Reasoning Models
- 2025-10; Zhengkai Lin, Zhihang Fu, Ze Chen, Chao Chen, Liang Xie, Wenxiao Wang, Deng Cai, Zheng Wang, Jieping Ye
High-Level Summary
- Thinking, Fast & Slow:
- Human cognition: fast & intuitive (System 1) or slow & deliberate (System 2)
- Authors introduce *dynamic thinking speed adjustment
- Controlling thinking speed:
- identify the steering vector that governs slow–fast thinking transitions in LRMs
- manually insert this to force slow/fast thinking
- Adjust for optimal performance:
- apply real-time difficulty estimation
- use this signal to tune application of steering vector
- The approach is training-free - "plug & play"
Elevator Pitch
Your mum has probably heard of Thinking, Fast and Slow (Daniel Kahneman, 2011). So has everyone in LLMs, and this is yet another paper with the same theme:
"How can we combine the advantages of both System 1 and System 2 thinking within one model, thus simultaneously achieving both efficiency and accuracy?"
The authors argue that some LRMs intrinsically possess both slow- and fast-thinking abilities. They observe that the slow and fast outputs consistently start with distinct opening words: "okay" or "alright" versus "to" or "first". This provides a built-in switch that can be manually activated. A principal component aligning with the "slow → fast" direction is found.
A dynamic reasoning speed control method is used: for each hidden layer , replace .
- : entices shorter, more concise responses
- : entices longer, more deliberate responses
Observing the Switch
The authors observe that some LRMs inherently exhibit both fast- and slow-thinking modes. They analyse the leading-word frequencies in top-100 shortest/longest responses by DeepSeek-R1-Distill-Qwen-7B on MATH-500.
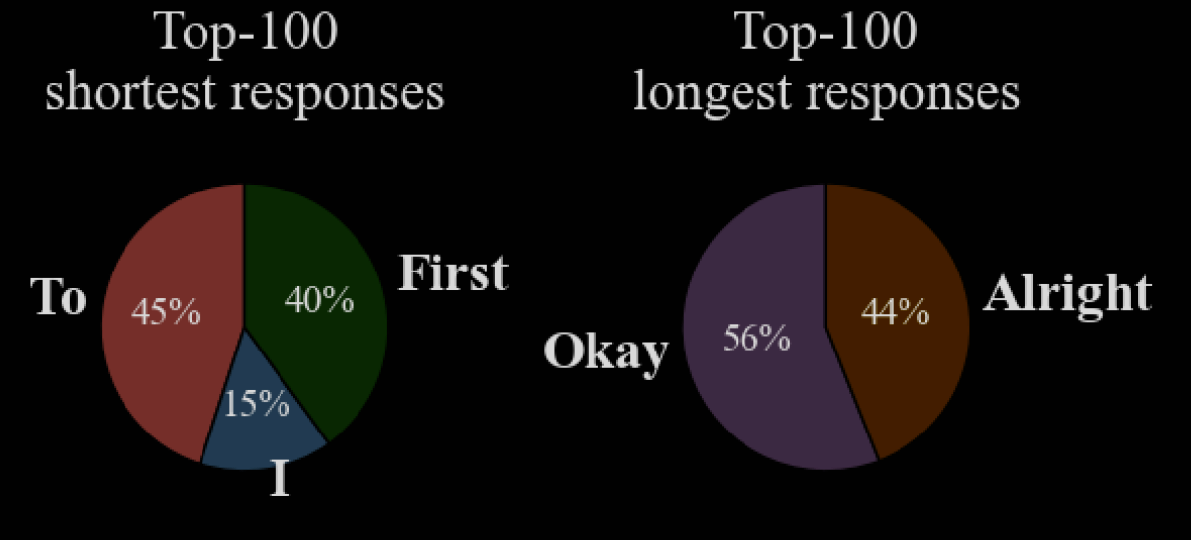
Given this fairly stark difference, they hypothesise that different leading words steer LRMs to long/short responses. This is investigated by seeding the response with different words - presumably "To" and "Okay", but unclear.
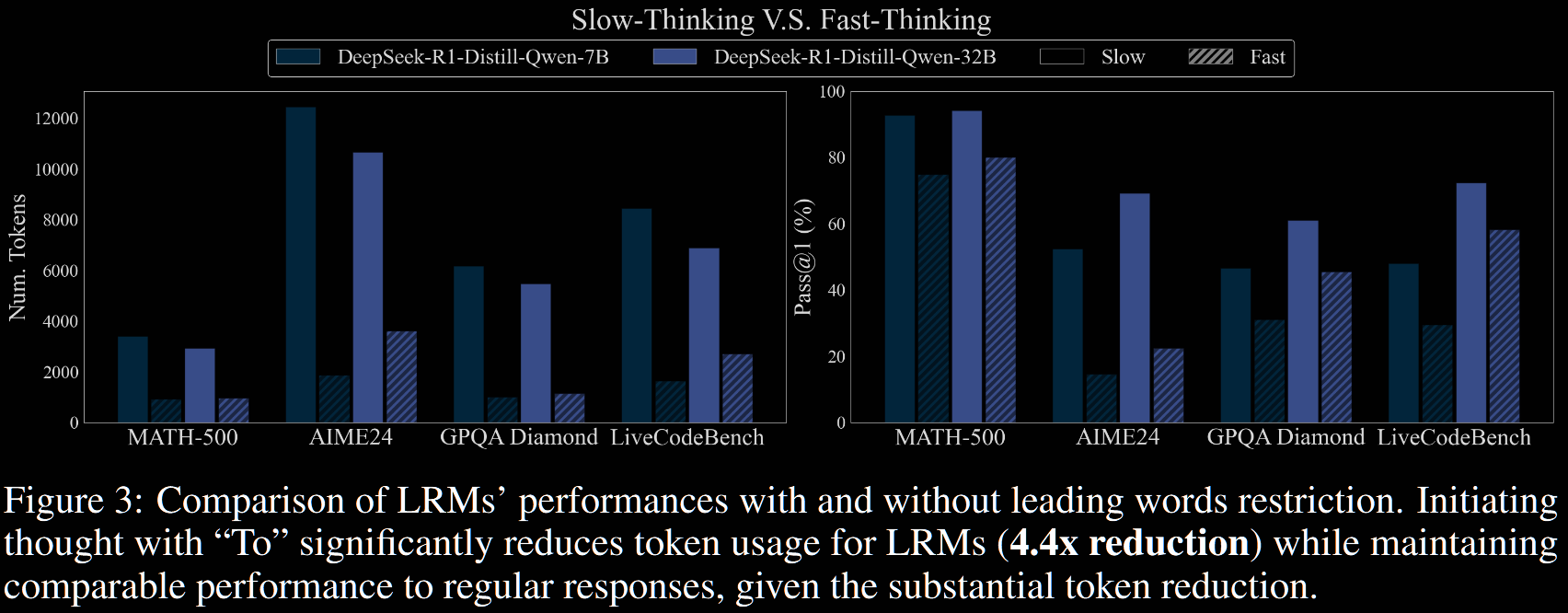
There is a pretty significant drop in both performance and token count in fast vs slow.
Finding, Extracting and Activating the Switch
RopE (uncited) claims that abstract cognitive functions are encoded as linear directions in LLMs' representation space. The authors hypothesise similarly that distinct reasoning are governed by a direction. Three stages are used to compute the vector.
-
Designing Stimuli. Given an input , the fast/slow response is used as the positive/negative stimulus, denoted .
-
Collecting Hidden Representations. For each layer, each input stimulus is processed, and the hidden states at the final position of the stimulus is collected.
-
Constructing the PCA Model. Denote the pairs collected in Step 2 as . For half the pairs, calculate the difference () and the other half the reverse (); this forms a dataset . The first principal component aligns with "slow → fast": and .
The vector is used as the steering vector. Specifically, at a given lager, the hidden state is modified with intensity :
- : shorter, most concise responses
- : more complex, deliberate reasoning
Experimental Results and Analysis
A collection of LRMs are benchmarked with differing values of .
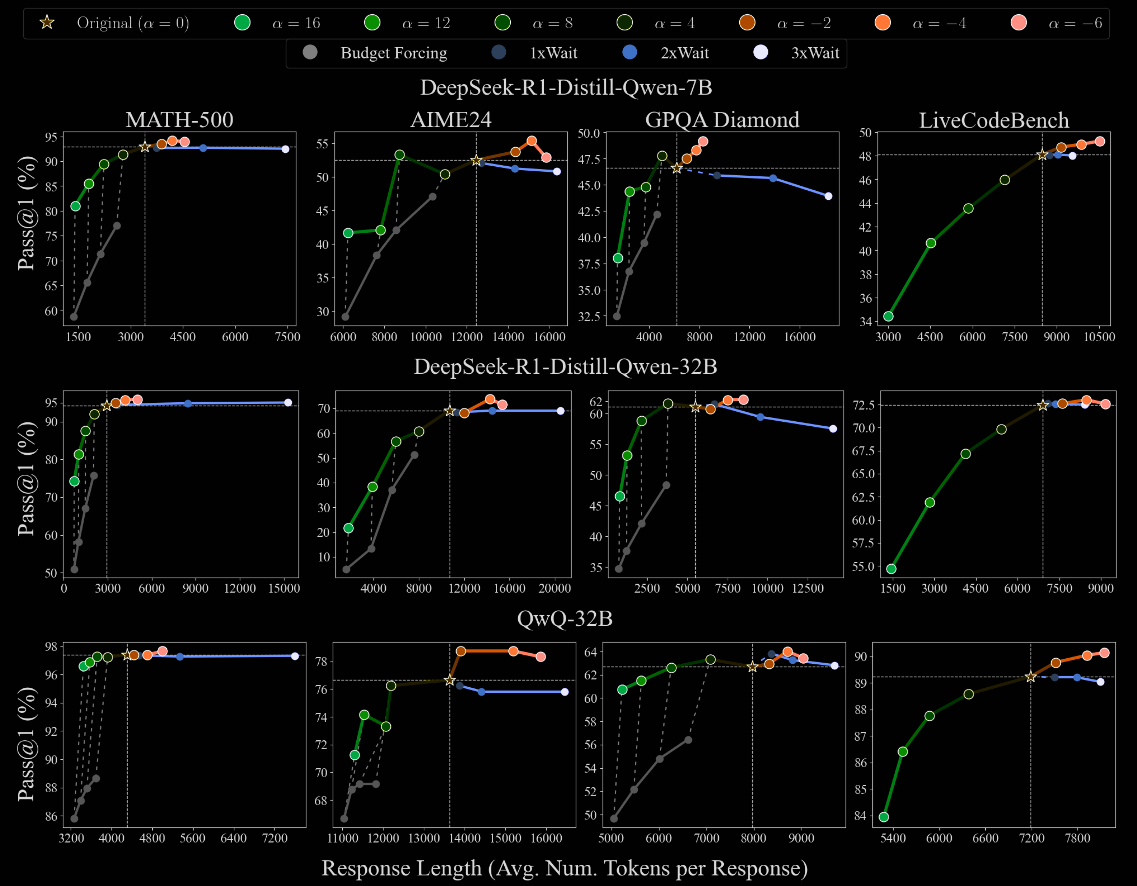
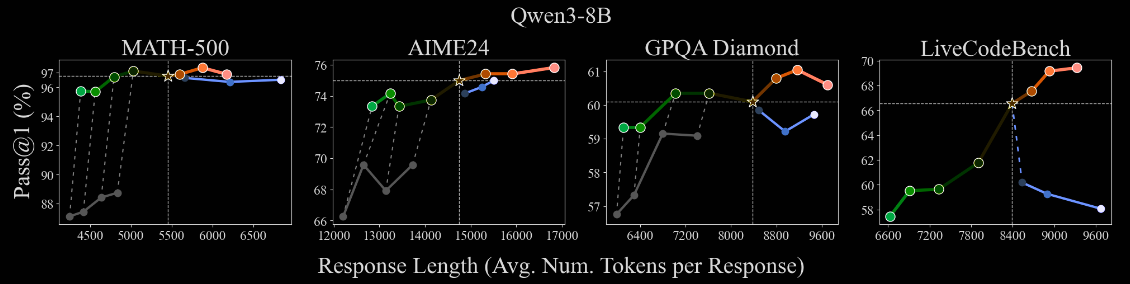
- All LRMs ultimate exceed their default performance when , but at an increased token cost. Further, the increase is normally fairly small.
- In some cases, such as QwQ-32B on MATH-500, there is only minimal performance loss when increasing , and decreasing the number of tokens. Admittedly, in this case, the benefit from is also small.
- In my opinion, the authors significantly oversell the results in their blurb following Figure 5.
Adaptive Control of Thinking Speed
The previous experiments fix throughout the run. Contrastingly, humans dedicate more/less computational energy to (perceived) difficult/easy parts. The goal of this section is to estimate the difficulty, and dynamically adjust accordingly.
The details are rather technical, not particularly clearly explained and, I feel, probably not super important. So, the reader is directed to §4 in the paper. Just the (apparently impressive) results are reported here, with a small amount of commentary. Throughout is restricted to .
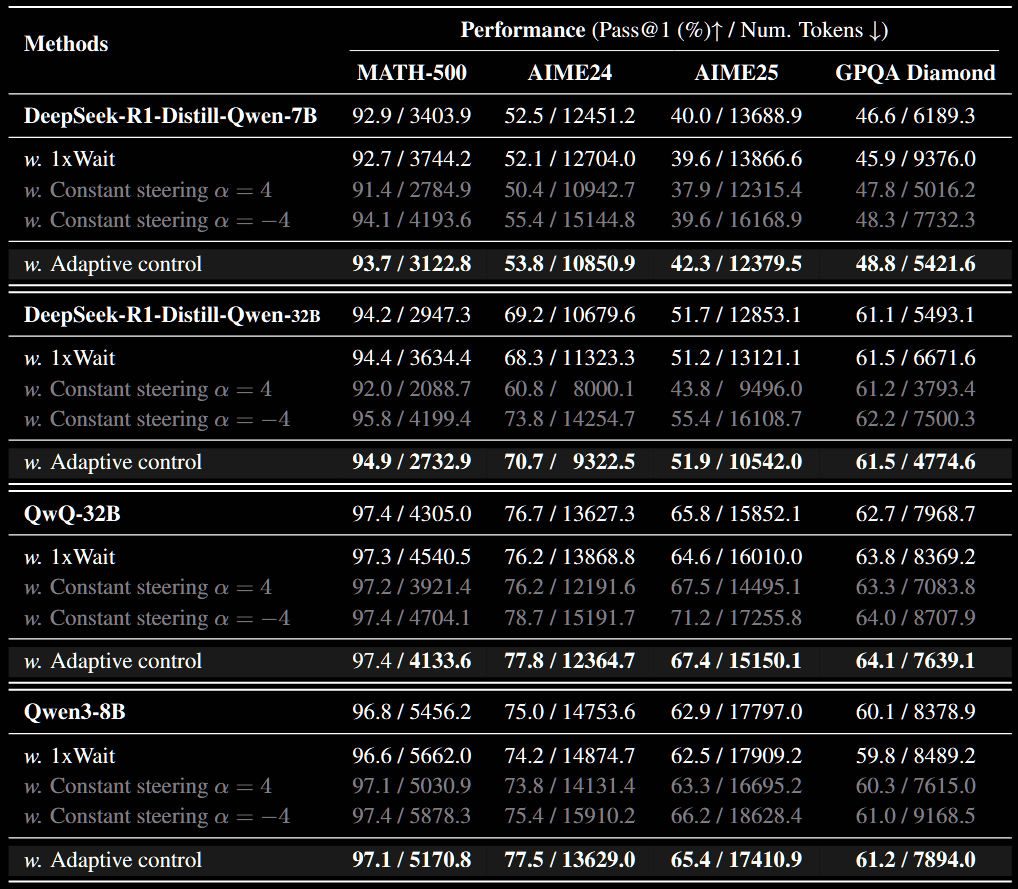
- Positive Aspects:
- The adaptive control typically outperforms the baseline with a smaller number of tokens used in all cases, bar one where they're both 97.4%
- This is a consistent improvement, not "good for some benchmarks, bad for others"
- Cause for Confusion/Concern:
- Adaptive also sometimes outperforms constant steering
- Even constant often outperforms the default, with the minimal number of tokens
- The uniform consistency, often under 1% improvement, is surprising - one might expect noise to prevent this uniformity
Conclusion
The paper makes a strong case for activating already-existing fast-/slow-thinking transitions. The training-free approach is much more natural than some of the somewhat ad-hoc soft thinking, mixture of inputs or similar approaches.
That said, the choice of steering vector is slightly ad-hoc, taking a selection of observed words. Perhaps this could be improved by trying to learn it? It is model-specific, though, which is a good start.
A clearer analysis of the adaptive case would be nice, with some kind of real-time estimate on the "thinking speed" - eg, 'effective '.
Overall, it is a decent paper, making a much more concrete case for "System 1 vs System 2" than many others that I've read.
PS: §8 Societal impact discussion
"We believe our work would inspire future research on the development of more efficient and intelligent AI systems. We foresee no negative societal impacts from our research[.]"
Well, that's good to know. Here I was, thinking there could be pros and cons. No, "no negative societal impacts".