Mixture of Inputs Summary
Text Generation Beyond Discrete Token Sampling
- 2025-05; Zhuang, Liu, Singh, Shang, Gao
High-Level Ideas
-
Training-free method that enables human-like 'fluid' reasoning before being articulated as natural language
-
Standard Chain-of-Thought (CoT) sample one token per step and follow that path, potentially abandoning valuable alternatives
-
Mixture of Inputs feeds both the sampled token and its probability distribution
-
A Bayesian method is used: the token distribution is the prior and the sampled token the observation*
-
It's related to superposition of all possible tokens: it's a convex combination, weighted by probabilities
-
This flexibility enables the exploration of different reasoning paths, and avoids making hard (consequential) decisions too early
*It's not clear to me how updating a prior from a draw from itself is helpful: how is the observation evidence of anything? See below for elaboration
Related Papers
-
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
-
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
Some Discussion
The underlying ideas are similar to soft thinking, but a little more refined. In vanilla Chain-of-Thought (CoT) prompting, the sampled intermediate reasoning token is fed back into the prompt. This is a one-hot encoding, and discards the information from the distribution; if a rare token is sampled, the bulk is forgotten. In essence, a single path is taken. Mixture of Inputs (MoI) feeds a distribution back into the LLM, namely, a mixture of the (one-hot encoded) sampled token and the underlying probability distribution. (Soft thinking uses only the distribution, and is called Direct Mixture here.)
The particular mixture is chosen through Bayesian inference: the distribution of the sampled token is the prior, and the sampled token the observation. No theoretical justification is given—unlike the approximations for soft thinking. Roughly, it feels to me that soft thinking is a bit too 'vague', trying to handle all (exponentially many) paths. MoI tries "[to balance] the concrete and the probabilistic aspects of cognition" by including the sampled token.
Some Details
Let denote the embedding of token . MoI feeds a mixture (convex combination)
Soft Thinking/Direct Mixture takes , where is the next-token distribution at step . Mixture of Inputs mixes this with the observed token. Let be the indicator that token is chosen. Let
where and is the normalised entropy:
Recall that the Dirichlet distribution is a continuous, multivariate probability distribution with pdf
If , then the total concentration increases as the uncertainty (of ) increases. Whilst the expectation doesn't depend on the (normalised) entropy , the variance does, but only weakly:
Instead of this exact formulation an estimation is used, with a concentration hyperparameter :
This can be formulated as
providing an interpolation between just the distribution (Direct Mixture/Soft Thinking) and just the token (CoT). The connection with the Dirichlet prior isn't so clear to me.
Results
In summary, I'd suggest the results are good, but far from outstanding: the average improvement is under 2pp (absolute) and 3% (relative), giving each model–benchmark pair equal weight.
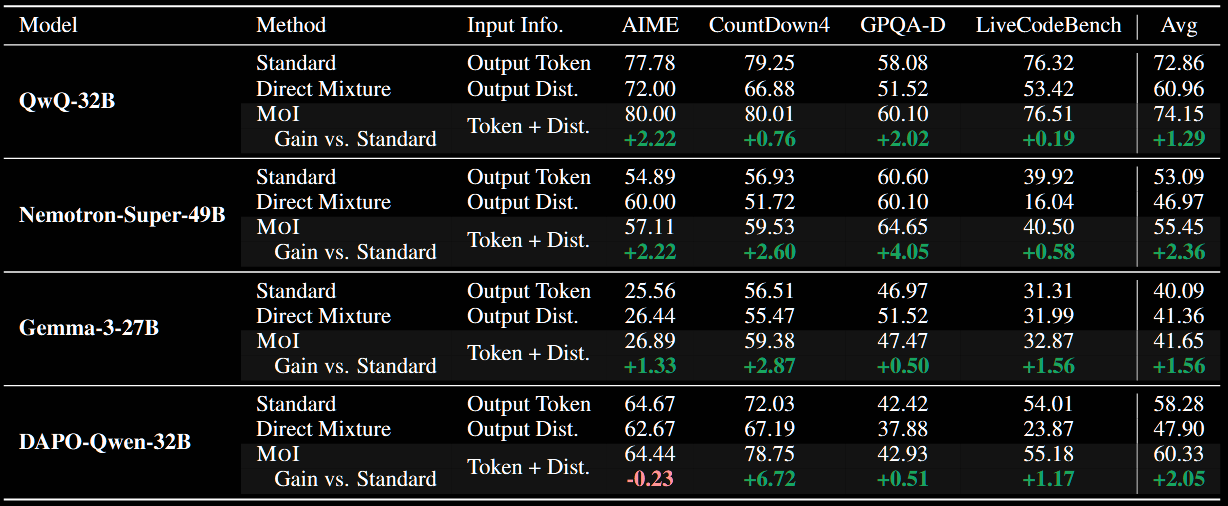
Comparison with Soft Thinking Paper
Interestingly, Direct Mixture frequently underperforms versus the baseline. This is somewhat in contradiction to the improvements seen in the Soft Thinking paper. The degradation is particularly pronounced for the Qwen models. The (model, benchmark) pair (QwQ-32B, GPQA-D) is used in both papers, but markedly different evaluations are reported in Soft Thinking.
- Soft Thinking paper:
- CoT baseline → 64.17
- CoT-Greedy → 65.15
- Soft Thinking → 67.17
- Mixture of Inputs paper:
- CoT baseline → 58.08
- Direct Mixture → 60.10
The results for QwQ-32B on LiveCodeBench are significantly different too. One potential difference is the lack of a cold stop in Direct Mixture versus the Soft Thinking paper.