COCONUT Summary
Training Large Language Models to Reason in a Continuous Latent Space
- 2024-12; Hao, Sukhbaatar, Su, Li, Hu, Weston, Tian
High-Level Ideas
-
Training-free method that enables human-like 'fluid' reasoning before being articulated as natural language
-
Standard Chain-of-Thought (CoT) sample one token per step and follow that path, potentially abandoning valuable alternatives
-
Most word tokens in a reasoning trace are for textual coherence, not the actual reasoning
-
Chain of Continuous Thoughts (COCONUT) avoids sampling the last token; rather, it feeds the hidden state back into
-
(The claim is that) COCONUT can perform a (type of) BFS, rather than committing to a deterministic path
-
Improvement is seen over no-CoT baseline, but standard CoT (with complete reasoning chains used to train the model) typically outperforms COCONUT
Related Papers
-
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
-
Text Generation Beyond Discrete Token Sampling (Mixture of Inputs)
-
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
- theoretical analysis of COCONUT, focused on graph-reachability
- shows COCONUT is able to keep possible solutions in superposition
-
Let Models Speak Ciphers: Multiagent Debate through Embeddings
Some Details
A standard LLM takes an input sequence and proceeds as follows, for .
- Embed the sequence up to time :
- Run the embedding through the tranformer to obtain the last hidden states at postition :
- Sample the next token using the LLM's head :
- The token is then embedded and is fed back in
Contrastingly, COCONUT directly utilises the last hidden states as the next input embedding. Special tokens <bot>/<eot> mark the beginning/end of the latent thought mode. Suppose this occurs between positions and —ie, and . When the model is in latent mode (ie, satisfies ), then .
The paper focuses on the question–answer regime. The usual negative log-likelihood loss is optimised during training, but the loss is masked on questions and latent thoughts. This does not (explicitly) encourage the continuous thought to compress the removed language thought, but rather facilitate the prediction of future reasoning.
COCONUT requires training, so that the outputs are appropriately aligned with the expected inputs. Reviewer qvXf proposed adding a trainable linear projection between the output and input; the authors said they tried this, but found minimal difference.
Results
In summary, the results aren't stellar, with CoT frequently outperforming COCONUT in accuracy, often by a large margin. However, the number of tokens generated by COCONUT is typically much smaller than for CoT.
A pre-trained GPT-2 is used as the base model for all the experiments. This is one of the major critiques of the paper: why evaluate on an old, small model? Four baselines are considered.
- CoT. The complete reasoning chains are used to train the LLM with supervised tine-tuning; during inference, reasoning chains are generated before outputting an answer
- No-CoT. The LLM is trained to directly generate the answer
- ICoT. Language reasoning chains are used in trainto to 'internalise' CoT; direct prediction is used in inference
- Pause. Training only uses questions and answers, no reasoning; special
<pause>tokens are inserted between these, potentially providing additional capacity to derive the answer
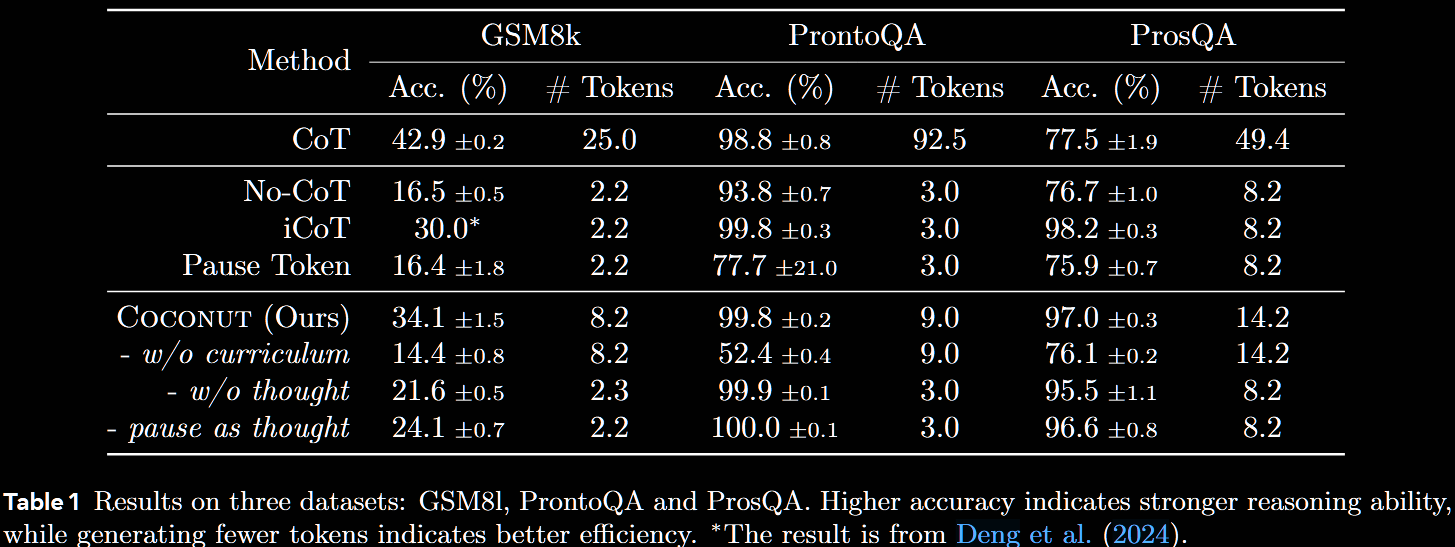
- GSM8k is a mathematical reasoning benchmark, at the level of primary and early-secondary school
- ProntoQA is a logical reasoning benchmark, requring the model to choose from multiple possible reasoning paths
- ProsQA is a variation on ProntoQA designed to have deeper branches
The model needs to switch from latent to language mode—ie, output <eot>. Two options were considered.
- Train a binary classifier on latent thoughts to enable autonomous termination.
- Always pad the latent thoughts to a constant length.
The authors report comparative performance, and so use the second, simpler version.
Critiques
The choice of model (GPT-2) was raised in the reviews. They only report COCONUT vs No-CoT, and do not mention the benchmark (🤦).
| Model | No-CoT | COCONUT | Improvement |
|---|---|---|---|
| Llama 3.2-3B | 26.0 | 31.7 | 5.7 (22%) |
| Llama 3-8B | 42.2 | 43.6 | 1.4 (3.3%) |
Regardless of the set-up, the increase over no CoT is minimal for the 8B model. They suggest that a potential reason is that continuous thoughts increase effective network depth, which may particularly benefit smaller models.
The continuous thoughts are fully differentiable, allowing for backpropagation. Some repetitive computation can be avoided using KV cache, but the sequential nature poses challenges for parallelisation. Further, a multi-stage training framework is required, to internalise from explicit to latent, which may restrict usability on larger models with longer reasoning chains.

Take-Aways
COCONUT is far from matching CoT in terms of accuracy (see Table 1). It has potential, however, to significantly shorten reasoning traces—not least by removing the need of textual coherence, but also simply by avoiding language altogether.
There are serious issues around the scalability of training, and the results in the paper attend only to GPT-2—the authors don't even say which one. Accuracy improvements on Llama 3-8B were much minimal (3.3% relative). The number of tokens were not reported.
Comparison with Soft Thinking and Mixture of Inputs
The soft thinking and mixture of inputs approaches are related, but fundamentally different. There, as well as in CoT, the softmax distribution is computed.
- CoT: a single token is sampled, embedded and fed back in
- Soft Thinking: the distribution is embedded (no sampling) and fed back in
- Mixture of Inputs: a mixture of the distribution and a (one-hot encoded) sample is used
- COCONUT: no distribution is calculated or embedded; the hidden state is fed directly in
COCONUT requires training to implement the new approach, whilst Soft Thinking and Mixture of Inputs are training free.