CIPHER Summary
Let Models Speak Ciphers: Multiagent Debate through Embeddings
- 2023-10; Pham, Liu, Yang, Chen, Liu, Yuan, Plummer, Wang, Yang
High-Level Ideas
- Training-free method that enables human-like 'soft' reasoning
- Standard Chain-of-Thought (CoT) sample one token per step and follow that path, potentially abandoning valuable alternatives
- CIPHER feeds the weighted average of all embedded tokens, weighted by the (softmax) LLM probability distribution, back in
- It also uses a debate approach:
- multiple agents provide a CIPHER response
- all of these are concatenated with the current prompt
- this is repeated for some number of rounds
- Bayesian optimisation is utilised to select the temperature
Related Papers
-
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
- soft thinking seems to be exactly the same idea
- current paper also has a debate element
-
Text Generation Beyond Discrete Token Sampling ("Mixture of Inputs")
-
Training Large Language Models to Reason in a Continuous Latent Space (COCONUT)
- feeds last hidden layer straight back into input
- doesn't go via (a weighted average in) the vocab space
-
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
- theoretical analysis of COCONUT, focused on graph-reachability
- shows COCONUT is able to keep possible solutions in superposition
Some Details
There are two main aspects of this paper:
- a new, 'non-verbal' approach CoT, feeding a mixture of tokens back in;
- a debate mechanism for improving responses.
Mixture of Tokens
A standard causal LLM generates tokens autoregressively based on the previous tokens. Given a and the first generated response tokens , it calculates a vector of logits , where is the embedding function and concatenates. The next token is then sampled from the vocab wrt
where is the temperature. This sampling discards all information in the probability distribution. CIPHER retains it, but plugging back in not the sampled token, but a weighted average of (the embeddings of) all tokens. Formally,
To emphasise, the embeddings need only be calculated once. There is no -th token which is to be embedded; rather the -th embedding is calculated directly as a convex combination of the (precalculated) vocab embedding.
The generation process stops when either of two conditions hold.
- The end-of-sequence (EOS) token embedding becomes the nearest neighbour to the newly generated embedding.
- The maximal sequence length is reached.
If the resopnse length is , the CIPHER response is .
Debate
The CIPHER debate procedure has the following steps.
-
Convert the question and instructions into embeddings .
-
For each debate round, form an embedding representation by concatenating and (possible) CIPHER responses, , from all debaters in previous rounds.
-
Feed this embedding representation into the models without the token decoding step. The debaters generate refine CIPHER responses, , following the previous procedure.
-
To close the debate, convert the embedding responses back to natural language using nearest-neighbour search over the vocabulary set, then aggregate.
This is visualised in the paper, in Algorithm 1.

Results
CIPHER is benchmarked against three baselines.
- Single Answer: a single LLM provides one response in natural language.
- Self-Consistency: a single LLM independently generates multiple responses (five here), then applies majority voting.
- Natural Language Debate: each LLM provides an initial response, then uses each other's response to refine their previous response.
The third baseline is closest to CIPHER, with the primary difference being the method of communication (sampled token vs distribution).
Most experiments are conducted using LLaMA2-70B, one of the largest open-source models available at the time. The evaluation is across five reasoning benchmarks.
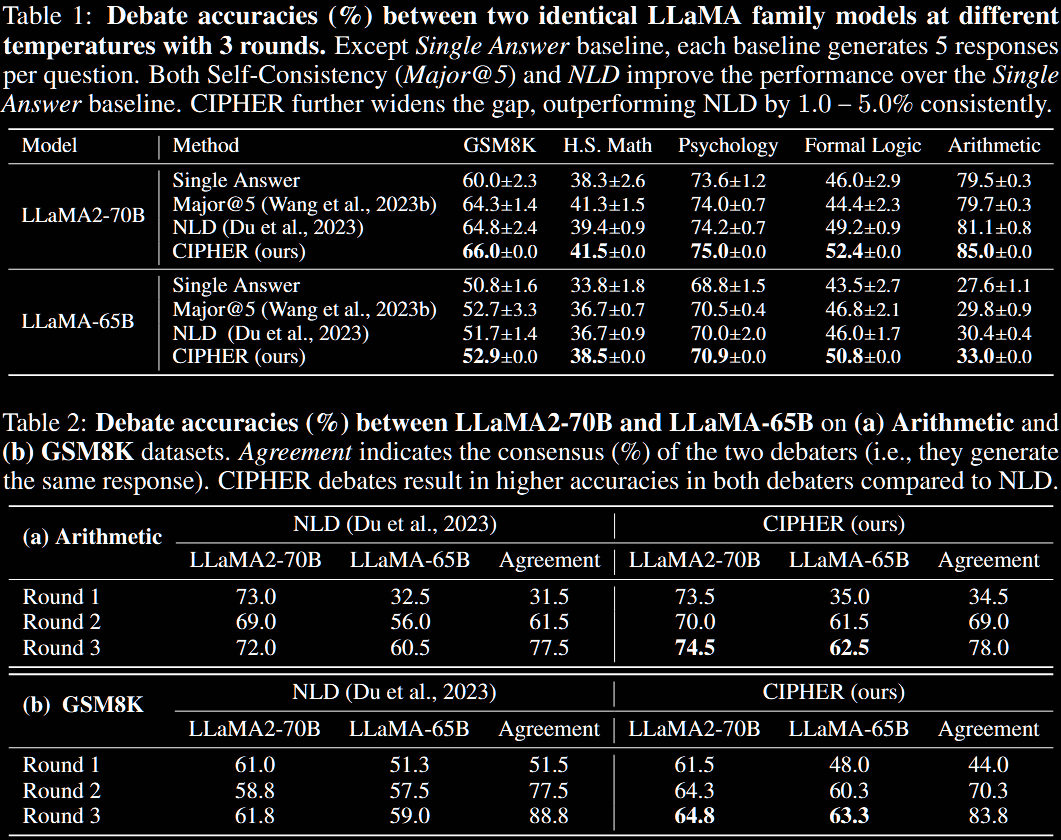
Table 1 uses two debating LLMs, from the same family. Table 2 has LLaMA2-70B and LLaMA2-65B debate each other; unsurprisingly, the 70B version performs worse when paired with a 65B (vs another 70B) and the 65B does better with a 70B (vs 65B).
An ablation study is also undertaken, but not described here; see Section 5.3 of the paper for details.